Pour s’assurer du bon fonctionnement d’une base de code, une bonne pratique est l’execution du code pour son analyse dynamique. On peut l’executer de différentes manières.
- Executer une fonction isolément dans autres en controllant les input et en vérifiant qu’un output est bien l’attendu : on parle alors de tests unitaires.
- Executer un scénario de test sur une chaine plus grande: si je demande confiture, alors l’application doit me renvoyer la bonne réponse. On parle alors de tests d’intégration.
- Executer un scénario de test concret: si je demande confiture, alors l’application doit me renvoyer la bonne réponse. On parle alors de tests fonctionnels si on est dans un environnement fermé ou test end to end en condition réelle.
- Executer un scénario de montée en charge : Si toutes les secondes quelqu’un demande a mon application différents objets, est ce que l’application va tenir le coup ou est ce que le service va s’arrêter. On parle alors de test de charge.
- Executer un scénario en évaluant la performance : Si je demande a l’application de la confiture, elle doit me répondre en moins de 1 secondes. C’est ici un test de performances.
Tests unitaires
Les tests unitaires sont les tests des fonctions de manière isolée. On entend ici de cette isolation que le contour des fonctions utilisées soit maitrisé et qu’il n’y ait pas de facteur extérieur pouvant altérer l’issue d’un test.
En cela, cela peut parfois être assez laborieux de tester une fonction, puisque l’on veut pouvoir couvrir unitairement tous les corner case qu’elle recouvre.
Exemple : pour une fonction qui renvoie la date du jour, l’on peut en effet vérifier qu’elle le fait selon le bon format, qu’elle le fait bien pour une année donnée et qu’elle renvoie une erreur si elle ne peut pas s’executer.
Pour ce qui est de la forme des tests, ils reposent sur des assertions: on souhaite valider le comportement d’une fonction au regard d’un attendu.
assert sum([1, 2, 3]) == 6, "Should be 6")
Unittest implémente un panel d’assertions que l’on peut faire.
L’usage le plus classique est le assertEqual()
Exemple :
import unittest
def add(a, b):
return a + b
class TestAdd(unittest.TestCase):
def test_add(self):
self.assertEqual(add(2, 3), 5)
self.assertEqual(add(-2, 3), 1)
self.assertEqual(add(2, -3), -1)
self.assertEqual(add(-2, -3), -5)
if __name__ == '__main__':
unittest.main()
Unittest permet l’extension de sa classe TestCase pour récupérer toutes les fonctions qui nous seront utiles dans le testing
Pour lancer les tests il faut effectuer la commande :
python3 -m unittest discover -s test -p "test_*.py"
Isolation des comportements : Mocking
En programmation , les mocks (simulacres ou mock object) sont des objets simulés qui reproduisent le comportement d’objets réels de manière contrôlée.
L’intêret de ces simulacres, c’est que l’on peut du coup isoler les parties des tests, pour que notre test ne teste réellement que la plus petite brique possible.
Un exemple :
J’utilise un webservice météo pour récupérer des infos, et ensuite effectuer un traitement sur ces données météo.
- L’API peut être indisponible, il faut donc un moyen résiliant de tester les fonctions qui l’utilisent.
- La météo change, si je veux pouvoir tester que ma fonction get_condition fonctionne bien par rapport a des données, et donc mettre une clause fixe d’assertion, je suis bloqué.
=> Mais je peux toujours faire en sorte d’interposer un wrapper qui me renvoie les données a un format connu.
La librairie unittest propose une implémentation du concept de Mock. Voici un exemple de ce que cela donnerait :
import unittest
from unittest.mock import MagicMock
import requests
def get_condition(city):
response = requests.get(f'https://weather.com/{city}')
weather = response.json()
return weather["condition"]
class TestWeatherApp(unittest.TestCase):
def setUp(self):
self.get_patcher = unittest.mock.patch('requests.get')
self.mock_get = self.get_patcher.start()
def tearDown(self):
self.get_patcher.stop()
def test_get_weather(self):
self.mock_get.return_value.json.return_value = {'temperature': 72, 'condition': 'sunny'}
weather = get_condition('San Francisco')
self.assertEqual(weather, 'sunny')
Pour les objets, il y a également la possibilité d’utiliser MagicMock, ce qui vous permet de reconstruire un objet custom avec fonctions et retours custom
Lien vers une documentation vulgarisant l'usage du mocking avec Pytest: https://pytest-with-eric.com/mocking/pytest-mocking/
Tests fonctionnels et End to End
L’idée des tests fonctionnels est de vérifier si l’application fonctionne et répond a un besoin exprimé.
Ils sont en général spécifiés comme des scénarios d’utilisation de l’application. Ils s’executent sur des environnements plus grands et sont donc plus difficiles a définir (souvent pour des cas plus généraux).
Typiquement cela reviendrait a lancer le serveur et a faire une requete dessus dans un processus parallèle.
- Cela peut s’executer simplement directement avec des outils comme requests et unittest :
import unittest
import requests
class TestApi(unittest.TestCase):
@classmethod
def setUpClass(cls):
import subprocess
cls.apiprocess = subprocess.Popen(["uvicorn", "main:app"])
cls.wait_for_api()
@classmethod
def tearDownClass(cls):
cls.apiprocess.terminate()
@classmethod
def wait_for_api(cls):
import time
url = "http://localhost:8000/"
delay = 1
attempts = 100
for _ in range(attempts):
try:
requests.get(url)
break
except requests.ConnectionError:
time.sleep(delay)
else:
raise TimeoutError(f"API didn't start in {delay*attempts} seconds")
def test_get_label_confiture_ok(self):
response_http = requests.get("http://localhost:8000/")
self.assertEqual(response_http.status_code,200)
Cela fonctionne pour une API. On pourrait également utiliser l’implémentation TestClient de FASTAPI our des tests fonctionnels et end to end (en condition réelles).
Fun fact : le saviez vous ? Vous faites des requêtes HTTP a chaque fois que vous parcourez des pages web.
Tests de charge
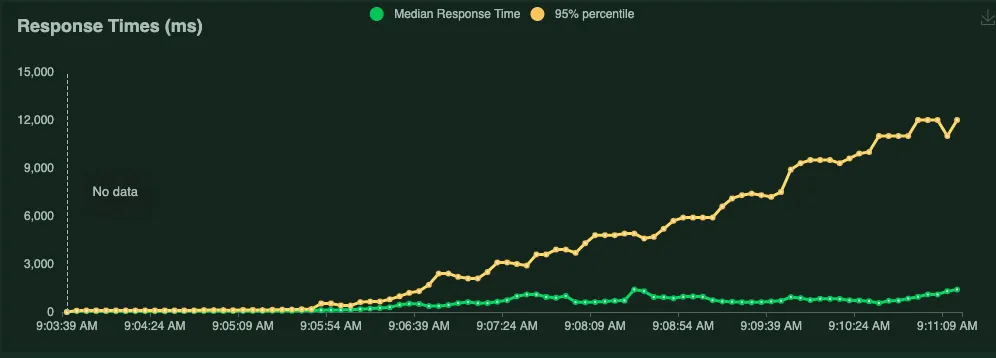 Les tests de charge permettent d'évaluer les performances d'un système, d'une application ou d'un site web en simulant une charge maximale ou une activité intense.
L'objectif principal est de déterminer comment l'applicatif réagit sous une pression ou une charge importante, en termes de temps de réponse, de capacité à gérer les demandes et de stabilité.
Bien évidemment on ne peut pas nécessairement être aussi proche d'un usage normal qu'en utilisant l'application (on parle alors d'atelier `stress test` ) mais l'objectif est de vérifier la capacité de montée en charge (nombre d'utilisateur) d'un applicatif.
Les tests de charge permettent d'évaluer les performances d'un système, d'une application ou d'un site web en simulant une charge maximale ou une activité intense.
L'objectif principal est de déterminer comment l'applicatif réagit sous une pression ou une charge importante, en termes de temps de réponse, de capacité à gérer les demandes et de stabilité.
Bien évidemment on ne peut pas nécessairement être aussi proche d'un usage normal qu'en utilisant l'application (on parle alors d'atelier `stress test` ) mais l'objectif est de vérifier la capacité de montée en charge (nombre d'utilisateur) d'un applicatif.Il existe une myriade d’outils pour effectuer des tests de charge sur les applicatifs. Dans le monde Java par exemple, l’option Jmeter et sa configuration XML est souvent choisi.
Pour python, il existe quelques projets et nous choisirons d’utiliser locust : https://locust.io/ qui est un projet assez récent et assez pratique à prendre en main pour réaliser des tests.
Locust permet de définir des tasks qui sont des templates de script python que l’on peut ensuite executer au travers d’une application web et faire monter en charge.
from locust import HttpUser, between, task
class WebsiteTest(HttpUser):
wait_time = between(1, 2)
@task
def index(self):
self.client.get("/")
L’objectif de ces outils de tests de charge est de vous permettre de tester sur des environnements réels l’arrivée de plus en plus massive d’utilisateur et de suivre les temps de réponse afin de repérer des limites.
Il est de bon ton lorsqu'on réalise ce genre de tests de s'outiller parallelement avec des outils de monitoring. De nombreux outils existent, et en python on pourra par exemple utiliser l'outil sentry : https://github.com/getsentry/sentry
TP : En repartant de l’API Predicat
Pour tester quelque chose, nous n’allons pas ici s’intéresser a tester un existant mais bien a développer une nouvelle fonctionnalité pour l’API predicat.
Cette fonctionnalité sera une fonctionnalité de cache sur la réponse de la prédiction, afin de gagner en efficacité.
En informatique moderne, pour répondre a un lot important de requêtes utilisateurs, différentes solutions existent (dénormalisation, cache)..
L’objectif du cache est de sauvegarder une réponse a une demande existante pour ne pas recalculer la réponse mais simplement renvoyer la réponse précédement émise.
Ce que ça donne c’est donc, dans le contexte global : définition d’un dictionnaire. Et alimentation de ce dictionnaire pendant le run et bypass de fonction si cela a déjà été calculé.
Exemple basique :
cache = {}
def get_in_cache_else_return(function, function_name, *args,**kwargs):
cache_key=f"{function_name}-{args}"
if cache_key in cache:
print("cache exists")
return cache[cache_key]
else:
cache[cache_key] = function(*args,**kwargs)
return cache[cache_key]
def a(b:int):
return b+1
print(get_in_cache_else_return(a,"a",1))
# 2
print(get_in_cache_else_return(a,"a",1))
# Cache exist | 2
Exercice 1 : Refactor pour ajout de la fonctionnalité de cache
Cette partie est là pour vous montrer l’idée d’un refactor.
Dans le fichier
main.py1 - On va faire un petit refactor : on va prendre l’intégralité du code ici :
if n == "all":
n = [i for i in config["models"]]
if type(n) == str:
n = [n]
output = {}
for nomenclature in n:
output[nomenclature] = {}
descriptions = sorted(set(q), key=q.index)
preprocessed_descriptions = [
preprocess_text(description) for description in descriptions
]
preds = predict_using_model(
preprocessed_descriptions, model=models[nomenclature], k=k
)
if v:
for pred in preds:
for pred_k in pred:
pred_k["label"] += " | " + full_dict.get(pred_k["label"], "")
for description, pred in zip(descriptions, preds):
output[nomenclature][description] = pred
Et le déplacer dans une fonction dédiée :
def predict_label_core(q:str,k:int,v:Optional[bool],n:Literal["na2008", "coicop", "na2008_old", "all"]):
if n == "all":
n = [i for i in config["models"]]
if type(n) == str:
n = [n]
output = {}
for nomenclature in n:
output[nomenclature] = {}
descriptions = sorted(set(q), key=q.index)
preprocessed_descriptions = [
preprocess_text(description) for description in descriptions
]
preds = predict_using_model(
preprocessed_descriptions, model=models[nomenclature], k=k
)
if v:
for pred in preds:
for pred_k in pred:
pred_k["label"] += " | " + full_dict.get(pred_k["label"], "")
for description, pred in zip(descriptions, preds):
output[nomenclature][description] = pred
Ainsi :
async def predict_label(
q: List[str] = Query(
...,
title="query string",
description="Description of the product to be classified",
),
k: int = Query(
1, title="top-K", description="Specify number of predictions to be displayed"
),
v: Optional[bool] = Query(
False, title="verbosity", description="If True, add the label of code category"
),
n: Literal["na2008", "coicop", "na2008_old", "all"] = Query(
"all", title="nomenclature", description="Classification system desired"
),
):
if n == "all":
n = [i for i in config["models"]]
if type(n) == str:
n = [n]
output = {}
for nomenclature in n:
output[nomenclature] = {}
descriptions = sorted(set(q), key=q.index)
preprocessed_descriptions = [
preprocess_text(description) for description in descriptions
]
preds = predict_using_model(
preprocessed_descriptions, model=models[nomenclature], k=k
)
if v:
for pred in preds:
for pred_k in pred:
pred_k["label"] += " | " + full_dict.get(pred_k["label"], "")
for description, pred in zip(descriptions, preds):
output[nomenclature][description] = pred
return output
devient :
async def predict_label(
q: List[str] = Query(
...,
title="query string",
description="Description of the product to be classified",
),
k: int = Query(
1, title="top-K", description="Specify number of predictions to be displayed"
),
v: Optional[bool] = Query(
False, title="verbosity", description="If True, add the label of code category"
),
n: Literal["na2008", "coicop", "na2008_old", "all"] = Query(
"all", title="nomenclature", description="Classification system desired"
),
):
return predict_label_core(q=q,k=k,v=v,n=n)
Ensuite il faut qu’on fasse notre cache :
Dans un fichier a côté cache_manager.py dans le dossier app
from typing import Callable
class CacheManager:
"""
classe simple qui permet, de stocker des résultats
"""
def __init__(self):
self.cache = {}
def get_in_cache_else_return(self,function:Callable, function_name, *args,**kwargs):
"""
Appelle une fonction si son nom et l'argument précisé n'a pas déjà été utilisé
Sinon va chercher dans le dictionnaire Cache la valeur stockée lors d'un précédent appel de fonction
"""
cache_key=f"{function_name}-{args}-{kwargs}"
if cache_key in self.cache:
return self.cache[cache_key]
else:
self.cache[cache_key] = function(args,kwargs)
return self.cache[cache_key]
cache_manager = CacheManager()
async def predict_label(
q: List[str] = Query(
...,
title="query string",
description="Description of the product to be classified",
),
k: int = Query(
1, title="top-K", description="Specify number of predictions to be displayed"
),
v: Optional[bool] = Query(
False, title="verbosity", description="If True, add the label of code category"
),
n: Literal["na2008", "coicop", "na2008_old", "all"] = Query(
"all", title="nomenclature", description="Classification system desired"
),
):
return cache_manager.get_in_cache_else_return(predict_label_core(q=q,k=k,v=v,n=n),"predict_label_core",q)
Exercice 2 : Validation par implémentation d’un test unitaire
La fonction de cache comme vu dans l’exemple plus haut, se teste indépendamment de la fonction appelée si non présent dans le cache.
- Implémentez un test avec une fonction que vous développerez pour vérifier que le cache_manager est fonctionnel
AIDE 1 (clickable): Aide avec spoiler
ça donne un truc du genre avec une fonction mock
from unittest import TestCase
from unittest.mock import Mock
from predicat.app.cache_manager import CacheManager
class TestCache(TestCase):
def test_cache_manager_ok(self):
"""
creation d'une mock fonction qui renvoie 1 puis 2 et verification que ça renvoie 2 fois 1
"""
mock_function = Mock(side_effect=[1,2])
cache_manager = CacheManager()
self.assertEqual(1,cache_manager.get_in_cache_else_return(mock_function,"mock_func",None,None))
self.assertEqual(1,cache_manager.get_in_cache_else_return(mock_function, "mock_func", None,None))
On notera bien qu’il y a un problème avec le fait que la fonction dépend du contexte et donc il manque l’implémentation d’une fonction statique.
Exercice 3 - Montée en charge de l’API
S’exercer sur locust a partir de la documentation disponible ici :
https://docs.locust.io/en/stable/index.html
- 1
pip install locust - 2 https://docs.locust.io/en/stable/writing-a-locustfile.html
Solution clickable
from locust import HttpUser, task, between
class ConfitureUser(HttpUser):
wait_time = between(1, 5)
@task
def get_confiture(self):
self.client.get("/label?q=confiture")
3 Démarrer l’api si elle n’est plus disponible
4 Requêter en augmentant la charge, l’url
Solution clickable
locust -f LEFICHIERQUEVOUSAVEZCREE
Testez ensuite sur votre application lancée en local en mode headless
Solution clickable
locust --headless --users 10 --spawn-rate 1 -H http://localhost:8000 -f LEFICHIERQUEVOUSAVEZCREE
https://docs.locust.io/en/stable/quickstart.html#direct-command-line-usage-headless