Accès aux exemples
Les exemples présentés sont accessibles directement sur le dépôt git associé : https://github.com/conception-logicielle-ensai/exemples-cours/tree/main/
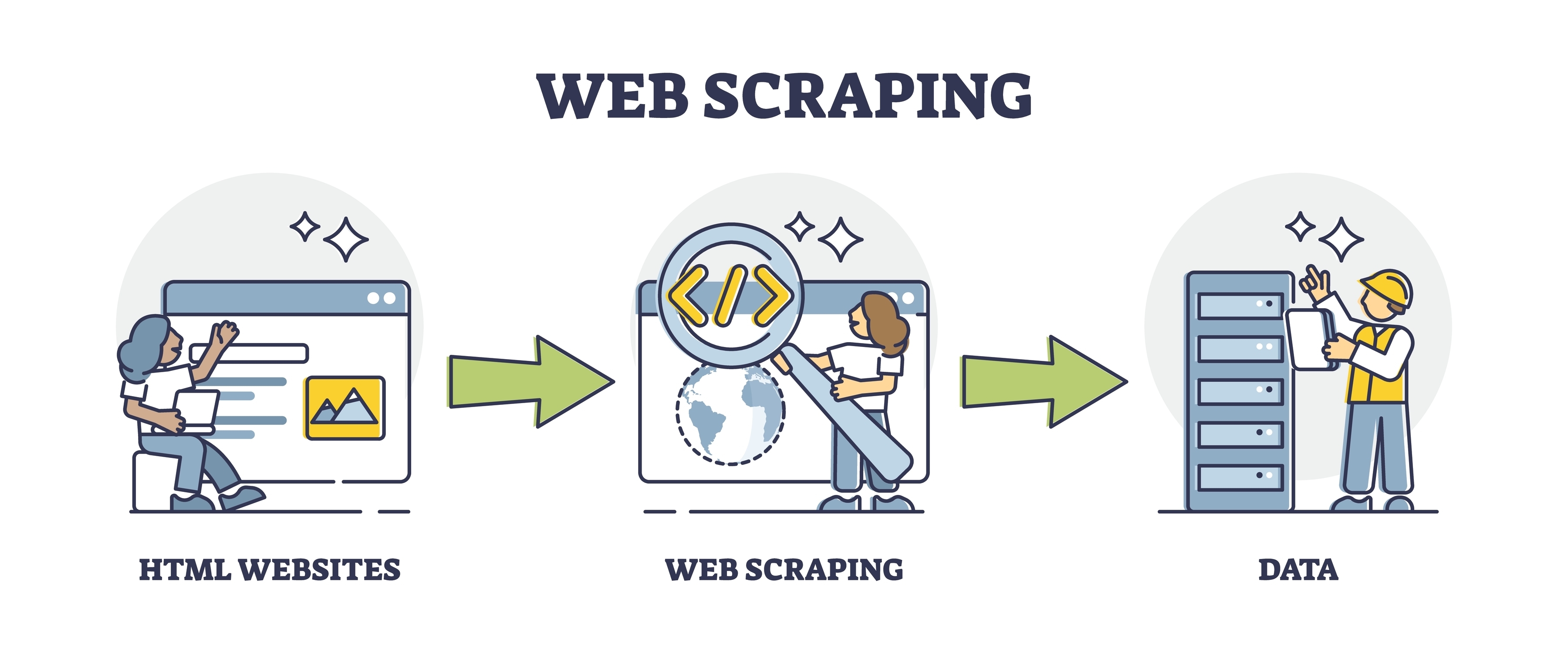
Introduction au Web Scraping#
Le web scraping désigne les techniques d’extraction de contenu depuis des sites internet. C’est une pratique que l’on envisage lorsque l’on a accès à des données publiquement disponibles, mais qu’aucun fichier fourni ou API n’est mis à disposition pour les exploiter.
Elle repose sur l’utilisation de clients HTTP pour traiter des données non formatées pour l’utilisation, typiquement des pages web accessibles aux utilisateurs au format HTML.
Le terme fait généralement référence à l’usage de bots pour collecter automatiquement ces contenus.
Le web scraping peut s’appréhender à travers des processus de type ETL (Extract, Transform, Load) :
- Extract : extraction des données brutes à partir de pages web.
- Transform : traitement des données brutes pour les rendre exploitables (
parsing). - Load : stockage des données dans un fichier, une base de données ou un autre format exploitable.
Exemples d’utilisation :#
- Suivi de prix : marchés, bourses, sites d’annonces, comparateurs de prix. Exemple : l’INSEE dans la section IPC.
- Récupération de données textuelles massives : commentaires, tweets, avis Google, etc.
- Récupération de listes de contacts : annuaires, Pages Jaunes, Pages Blanches, bases de sondage d’entreprises.
Webscrapping et légalité : existence d’une zone grise#
Le webscraping est l’une des pratiques les plus courantes pour la récupération de données sur le web. Le web scraping permet d’extraire des données disponibles publiquement, mais certaines données sont protégées par le droit d’auteur, et d’autres concernent des informations personnelles, soumises à des règles de confidentialité. C’est ce qui explique qu’il y a là une zone grise.
Droit des données :#
En Europe, actuellement il y a la General Data Protection Regulation (GDPR) (ou RGPD) qui protègent les données personnelles mais ne précisent pas le traitement dans le cas d’usage du webscraping.
Aux états unis : California Privacy Rights Act (CPRA), c’est une loi en californie, mais rien n’existe côté fédéral sur le droit des données.
Il est donc préférable d’utiliser des APIs au maximum pour la récupération de données lorsque celles-ci sont disponibles.
Même si le web scraping est légal sous certaines conditions, les sites web peuvent mettre en place des mécanismes techniques pour se protéger contre le scraping abusif.
Protection contre le webscrapping : Humaniser nos processus#
La récupération de données en utilisant du webscrapping peut s’assimiler à une attaque informatique de type DDOS (Denial Of Service).
Ainsi certains sites ont mis en oeuvre des solutions pour se protéger contre le DDOS et le webscraping abusif. Ces solutions reposent sur les principes suivants :
- Les sites bloquent des requêtes répétées sur des intervalles de temps trop proches venant d’une même IP (~même machine)
- Les sites modifient contenu des balises html pour empêcher l’automatisation
- Création de
Honeypot: liens invisibles que seul un bot “cliquerait” pour bloquer les bots/botteurs. - Authentification exigée au bout d’un certain nombre d’usages.
Ils proposent donc différentes guidelines générales pour les utilisateurs qui souhaitent webscraper :
Respecter les règles définies par le site : Les sites indiquent souvent ce que les robots sont autorisés à faire via le fichier
robots.txt. Par exemple : https://www.google.com/robots.txt. Avant de scraper un site, il est important de consulter ce fichier et de respecter ses directives.Espacer les requêtes : Pour éviter de surcharger les serveurs, il est recommandé de laisser un intervalle entre chaque requête. Cela réduit les risques de blocage et limite l’impact sur les performances du site.
Choisir les périodes de faible trafic : Éviter de lancer des requêtes pendant les heures de forte activité du site. Par exemple, pour les administrations ou services publics français, il est préférable de planifier le scraping la nuit ou pendant des périodes où le service est moins sollicité.
Récupération des données : Client HTTP#
Les clients http sont nécessaires pour la récupération des données exposées sur les sites. Il en existe de différents types.
Client en ligne de commande#
Les outils comme Wget et cURL permettent d’envoyer des requêtes HTTP directement depuis le terminal.
cURL: Supporte plusieurs protocoles (HTTP, FTP, etc.), permet d’envoyer des requêtes GET, POST, etc.Wget: Principalement utilisé pour télécharger des fichiers depuis le web.
Ils permettent de scripter des requêtes et sont disponibles sur la plupart des OS.
Remarque
Nous vous avons présenté curl dans la session précédente. Il est très utile puisqu’il est commun d’échanger des commandes curl entre des équipes de développeur (DEV) ou des équipes de maintenance d’infrastructure (OPS).
Clients utilitaires#
Il existe des clients utilitaires comme Insomnia et Postman offrent une interface graphique pour tester des API REST.
Postman: Permet d’envoyer des requêtes HTTP, d’automatiser des tests et de documenter des API.Insomnia: Similaire àPostman, axé sur la simplicité et l’expérience utilisateur.
Pour aller plus loin
Ils peuvent être très pratiques si vous travaillez avec des collègues ne maitrisant pas python puisque vous pouvez leur partager vos scripts.
Navigateur et utilisation des outils de développement#

Les navigateurs sont des clients HTTP très adaptés pour effectuer des requêtes HTTP. Ils proposent par ailleurs une interface de dévtools directement incorporée.
Ils proposent :
- Un onglet Réseau : Cela permet de traquer les requêtes HTTP effectuées par le navigateur. Cela peut être utile pour les stocker ou les reproduire via script.
- Un onglet debug : interface debug côté client (nos pages executant du javascript, cela permet de comprendre un bug d’affichage par exemple)
- Une console : elle permet d’executer du javascript sur la page
- Un inspecteur : permet de scanner les éléments et de récupérer des informations sur celles ci.
…Et d’autres fonctionnalités..
Consultons ensemble cette documentation :
Pour aller plus loin
Lien vers une vidéo présentant les outils de développements chrome : https://www.youtube.com/watch?v=BrsyIyYSP1c
Utilisation de requests#
Pour effectuer des requêtes http, on utilisera la librairie client http requests.
Les requêtes seront cette fois effectuées pour la récupération de pages web, pour récupérer des fichiers HTML bruts, et donc on privilégiera la récupération du text dans les réponses :
import requests
URL_COURS = "https://conception-logicielle.abrunetti.fr/"
response = requests.get(URL_COURS)
print(response.text) # Affiche le contenu HTML de la pageUtilisation d’un script dans une page HTML (Javascript)#
En javascript il existe de nombreux client HTTP, nous privilégierons l’usage d’axios en seconde partie du cours, mais le client http “de base” est fetch :
Observez plutôt en récupérant le code source de la page d’accueil du cours :
Code source html / js avec la librairie `fetch`
<div id="fetch-with-fetch">
<button id="fetch-btn" style="display: inline-block; padding: 10px 20px; background-color: #007bff; color: white; font-size: 16px; border-radius: 5px; cursor: pointer; text-align: center; font-family: Arial, sans-serif;" onclick="fetchPageFetch()">Charger la page avec le package fetch</button>
<div id="fetch-content" style="white-space: pre-wrap; border: 1px solid #000; padding: 10px; margin-top: 10px;"></div>
<script>
async function fetchPageFetch() {
const url = "https://conception-logicielle.abrunetti.fr/";
try {
const response = await fetch(url);
if (!response.ok) {
throw new Error(`Erreur: ${response.status}`);
}
const text = await response.text();
document.getElementById("fetch-content").textContent = text;
} catch (error) {
document.getElementById("fetch-content").textContent = "Erreur lors du chargement: " + error.message;
}
}
</script>
</div>Pour simplifier la gestion des requêtes HTTP et éviter de devoir construire manuellement les URLs, ce cours recommande l’utilisation de Axios, une librairie qui facilite les requêtes, la gestion des erreurs et des paramètres. Voici un exemple d’utilisation pour récupérer le contenu d’une page web statique.
Code source html / js avec la librairie axios
<div id="axios">
<script src="https://cdn.jsdelivr.net/npm/axios/dist/axios.min.js"></script> <!-- Import Axios -->
<button id="axios-btn" style="display: inline-block; padding: 10px 20px; background-color: #007bff; color: white; font-size: 16px; border-radius: 5px; cursor: pointer; text-align: center; font-family: Arial, sans-serif;" onclick="fetchPageAxios()">Charger la page avec le package axios</button>
<script>
async function fetchPageAxios() {
const url = "https://conception-logicielle.abrunetti.fr/";
try {
const response = await axios.get(url);
document.getElementById("axios-content").textContent = response.data;
} catch (error) {
document.getElementById("axios-content").textContent = "Erreur lors du chargement: " + error.message;
}
}
</script>
<div id="axios-content" style="white-space: pre-wrap; border: 1px solid #000; padding: 10px; margin-top: 10px;"></div>
</div>Remarque, c’est exactement la même base de code pour la récupération de données depuis une API, ce qui d’ailleurs est plus fréquent en JS.
Web Crawling: exemple avec Selenium#

Le web crawling est un autre mode de webscraping, l’objectif ici est d’utiliser un site web et de le parcourir comme un utilisateur a l’aide d’un script. Cela peut être très utile lorsque vous désirez extraire des données d’un site qui nécessite une authentification, ou que vous désirez réaliser des scénarios plus complexes d’extractions.
Cela est également très utile pour tester les fonctionnalités côté Frontend, a partir d’une url.
Selenium est un outil qui permet d’executer des actions scriptées comme le parcours de pages sur des interfaces web, il est très utilisé et possède une intégration dans différents languages : java, python, javascript,..
Fonctionnellement, Selenium s’appuie sur les driver de navigateur pour lancer en tâche de fond ou en interactif un navigateur a partir duquel il va pouvoir interagir avec les pages web.
Pour l’installer il faut donc :
Pour les exemples, on utilise gecko, le webdriver de firefox
Les cas d’utilisation de sélénium est le parcours de page pour récupérer des informations :
Un Exemple : récupération des plateformes et projection sur lesquelles sont diffusées les films,voir https://github.com/conception-logicielle-ensai/exemples-cours/blob/main/cours-5/webscrapping/recuperation_donnees/selenium_exemple.py
Tests fonctionnels De la même manière, on peut effectuer des tests de non regression et des tests d’intégration sur nos applications frontend et nos API avec selenium. Il suffit de vérifier qu’en allant a une adresse connue, on ait des éléments de réponse attendus valides.
Extraction de données HTML : str, regex et parsing#
Une fois les pages récupérées, les données ne sont pas directement exploitables, elles nécessitent un retraitement pour isoler l’information utile des éléments d’affichage (balises, styles, scripts…).
Par exemple, on peut vouloir aggréger les indicateurs récupérés ou préparer des données textuelles pour ensuite pouvoir entrainer un modèle sur ces données.
Extraction simple avec les fonctions natives de str#
On peut extraire des informations manuellement avec les fonctions natives Python sur les chaînes de caractères (str) : find, replace, boucles, etc.
Exemple : récupérer les titres des parties de cours dans une page HTML
import requests
H2_OPEN_TAG = "<h2>"
H2_CLOSE_TAG = "</h2>"
LEN_H2_OPEN = len(H2_OPEN_TAG)
LEN_H2_CLOSE = len(H2_CLOSE_TAG)
def extraction_noms_cours_raw(html: str) -> list[str]:
"""
Extrait les titres des cours depuis les balises <h2> contenues
dans les <article>.
Parsing volontairement naïf basé sur les chaînes.
"""
titres: list[str] = []
position = 0
while True:
h2_start = html.find(H2_OPEN_TAG, position)
if h2_start == -1:
break
h2_end = html.find(H2_CLOSE_TAG, h2_start)
if h2_end == -1:
break
titre = html[
h2_start + LEN_H2_OPEN :
h2_end
].strip()
titres.append(titre)
position = h2_end + LEN_H2_CLOSE
return titres
# Exemple d’utilisation
URL_COURS = "https://conception-logicielle.abrunetti.fr/cours/"
response = requests.get(URL_COURS)
html = response.text
print(extraction_noms_cours_raw(html))
# ['Git Avancé', 'Architecture applicative', 'Gestionnaire de package, partage de code, industrialisation', "Configuration du code en fonction de l'environnement", 'Bonnes pratiques du développement et design patterns', "Outils d'analyse statique d'une base de code", "Analyse dynamique d'une base de code", 'Automatisation des contrôles sur une base de code versionnée', "HTTP: Consommation et construction d'API webservice", 'Récupération de données via le webscraping']Limites :
- Fragile face aux modifications de structure HTML (ajout de classes, espaces, sauts de ligne…).
- Peu efficace pour des pages longues ou complexes.
Extraction avec les expressions régulières (Regex)#

Les expressions régulières, ou regex pour faire court, sont des motifs que l’on utilise pour rechercher et manipuler du texte. On parle souvent de pattern matching.
L’idée est de créer un modèle qui va correspondre à des ensembles cohérents de chaînes de caractères.
Pourquoi utiliser les regex ?
- Identifier et extraire des données à l’intérieur de balises HTML ou XML.
- Rechercher des occurrences de mots ou motifs spécifiques dans de longues chaînes de texte.
- Valider ou filtrer des informations (emails, numéros de téléphone, codes…).
Les regex ne servent pas uniquement au web scraping : elles sont utiles dans tous types de traitement de texte.
Utiliser les regex avec Python#
Python propose le module re dans sa bibliothèque standard pour travailler avec les expressions régulières.
import reSyntaxe de base#
Ancres
| Ancres | Description |
|---|---|
^ | Début de ligne. Correspond au début d’une chaîne. |
$ | Fin de ligne. Correspond à la fin d’une chaîne. |
\b | Limite de mot. Correspond à la position entre un caractère de mot (\w) et un caractère non-mot. |
Symboles spéciaux
| Symbole spécial | Description |
|---|---|
. | Correspond à n’importe quel caractère sauf un saut de ligne. |
* | Correspond à zéro ou plusieurs occurrences du caractère précédent. |
\d | Correspond à un chiffre (équivalent à [0-9]). |
\D | Tout caractère qui n’est pas un chiffre ([^0-9]). |
\w | Caractère alphanumérique ([a-zA-Z0-9_]). |
\W | Tout caractère non-alphanumérique ([^a-zA-Z0-9_]). |
\s | Caractère d’espacement (espace, tabulation, retour à la ligne). |
\S | Tout caractère qui n’est pas un espacement. |
Exemples simples
^abc → "abc" au début de la ligne
xyz$ → "xyz" à la fin de la ligne
\d{3} → trois chiffres consécutifs
\w+ → un ou plusieurs caractères alphanumériques
^toto.* → toute ligne qui commence par "toto"Groupes de capture#
Les groupes de capture permettent d’isoler une portion spécifique d’un motif. Ils sont définis avec des parenthèses ( ).
| Expression régulière | Description |
|---|---|
(.*) | Capture toute la chaîne |
<li>(.*?)</li> | Capture tout ce qui est entre <li> et </li> |
Récupération des groupes
\0→ correspond au match complet\1→ premier groupe capturé\2→ deuxième groupe capturé, etc.
Exemple concret en Python#
import re
texte = """
<ul class="liste-cours">
<li>Cours 1 - Architecture logicielle avancée</li>
<li>Cours 2 - Conception orientée objet et principes SOLID</li>
<li>Cours 3 - Tests automatisés et intégration continue</li>
</ul>
"""
# Deux groupes : le tag ouvrant et le contenu
pattern = r"(<li>)(.*?)</li>"
match = re.search(pattern, texte)
if match:
print("Groupe 0 :", match.group(0)) # <li>Cours 1 - architecture</li>
print("Groupe 1 :", match.group(1)) # <li>
print("Groupe 2 :", match.group(2)) # Cours 1 - architectureExemple pratique : extraire des titres de cours#
import re
import requests
def extract_with_regex(html, pattern):
"""
Récupération de toutes les données correspondant à un pattern regex
"""
matches = re.findall(pattern, html, re.DOTALL)
return [match.strip() for match in matches]
# Tous les titres
pattern_titre_cours = r"<h2>(.*?)</h2>"
# Titres commençant par A
pattern_titre_cours_commencant_par_a = r"<h2>(A.*?)</h2>"
URL_COURS = "https://conception-logicielle.abrunetti.fr/cours/"
response = requests.get(URL_COURS)
html = response.text
titre_cours = extract_with_regex(html, pattern_titre_cours)
titre_cours_commencant_par_a = extract_with_regex(html, pattern_titre_cours_commencant_par_a)
print("Tous les titres :", titre_cours)
# Tous les titres : ['Git Avancé', 'Architecture applicative', 'Gestionnaire de package, partage de code, industrialisation', "Configuration du code en fonction de l'environnement", 'Bonnes pratiques du développement et design patterns', "Outils d'analyse statique d'une base de code", "Analyse dynamique d'une base de code", 'Automatisation des contrôles sur une base de code versionnée', "HTTP: Consommation et construction d'API webservice", 'Récupération de données via le webscraping']
print("Titres commençant par A :", titre_cours_commencant_par_a)
# Titres commençant par A : ['Architecture applicative', "Analyse dynamique d'une base de code", 'Automatisation des contrôles sur une base de code versionnée']Parsing HTML avec BeautifulSoup#

Pour un parsing plus stable et robuste, on utilise BeautifulSoup, une librairie externe :
uv add beautifulsoup4from bs4 import BeautifulSoup
import requests
url = "https://conception-logicielle.abrunetti.fr/cours/"
res = requests.get(url)
html = res.text
soup = BeautifulSoup(html, "html.parser")BeautifulSoup permet de naviguer dans l’arborescence HTML et d’extraire facilement les éléments souhaités.
Sélection avec CSS ou structure HTML#
Supposons qu’on a ce fichier HTML :
<html>
<head>
<title>Catalogue des cours</title>
</head>
<body>
<!-- En-tête de la page -->
<main class="container">
<section class="intro">
<h2 class="page-title">Ensemble des modules du cours</h2>
<p>
Retrouvez ici l’ensemble des ressources liées à la conception
logicielle moderne.
</p>
</section>
<!-- Liste des cours -->
<section class="course-grid">
<article class="course-card">
<a href="/cours/git-avance">
<h2>Git Avancé</h2>
</a>
<p class="description">
Maîtriser Git dans un environnement professionnel.
</p>
<span class="reading-time">25 min</span>
</article>
<article class="course-card">
<a href="/cours/architecture-applicative">
<h2>Architecture applicative</h2>
</a>
<p class="description">
Structurer une application maintenable et testable.
</p>
<span class="reading-time">30 min</span>
</article>
<article class="course-card">
<a href="/cours/configuration-env">
<h2>Configuration selon l’environnement</h2>
</a>
<p class="description">
Adapter son code aux contextes d’exécution.
</p>
<span class="reading-time">20 min</span>
</article>
</section>
<!-- Navigation -->
<nav class="pagination">
<ul>
<li><a href="/cours?page=1">1</a></li>
<li><a href="/cours?page=2">2</a></li>
<li><a href="https://externe.com">Lien externe</a></li>
</ul>
</nav>
</main>
</body>
</html>- Pour récupérer tous les
<h2>à l’intérieur de<article>:
from bs4 import BeautifulSoup
html = """ ...HTML ci-dessus... """
soup = BeautifulSoup(html, "html.parser")
titres = [
h2.get_text(strip=True)
for h2 in soup.select("article h2")
]
print(titres)- Pour récupérer tous les liens
<a>de la page
links = [a["href"] for a in soup.find_all("a", href=True)]
print(links)Plus de documentation, dans la documentation oficielle
Pour aller plus loin
Pour aller plus loin
Un autre outil très complet pour des projets python : scrapy
Ressources externes (pour aller plus loin)#
- Très bonne formation par Antoine Palazzo sur le webscrapping : https://inseefrlab.github.io/formation-webscraping
- Cours de datascience ENSAE, cours de web scrapping par Lino Galliana: https://pythonds.linogaliana.fr/content/manipulation/04a_webscraping_TP.html
Exercice secret :
Dans cette page est caché un contenu qui contient différentes valeurs. Récupérez le contenu de cet élément caché et sommez les valeurs.
- A l’aide de votre navigateur et de votre console développeur, trouver l’
iddu contenu caché sur cette page Quel est le résultat de cette somme ?
2595677
2609777
2609997
- 1290908
- 1290918
- 12908
- 919
- 21
- 3