

Contexte#
Cette section présente les enjeux et les principes fondamentaux du déploiement applicatif, à travers un cas concret d’hébergement dans le cloud reposant sur Kubernetes.
Les exemples s’appuient sur :
une interface utilisateur (frontend) accessible à l’adresse suivante : https://users-ensai.kub.sspcloud.fr
une API (backend) accessible à l’adresse suivante : https://api-users-ensai.kub.sspcloud.fr
Le code source complet de l’application est disponible dans le dépôt GitHub du projet
archi-exemple: https://github.com/conception-logicielle-ensai/archi-exemple
Préambule : hébergement traditionnel d’une application#

Avant d’aborder ce que permet Kubernetes, il est nécessaire de rappeler ce que signifie, plus généralement, héberger une application ou un site web.
Environnement d’exécution#
Toute application nécessite un environnement d’exécution : il s’agit du support matériel et logiciel sur lequel elle peut être lancée.
Cela comprend notamment :
- l’installation des dépendances (langages, bibliothèques, frameworks) ;
- la configuration des services nécessaires ;
- la gestion des fichiers applicatifs.
Cet environnement peut prendre différentes formes, par exemple :
- un ordinateur personnel sur lequel Python est installé ;
- un serveur physique sur lequel est installé un moteur Docker, permettant d’exécuter des applications sous forme de conteneurs.
Routage et exposition de l’application#
Une fois l’application en cours d’exécution dans son environnement, il faut la rendre accessible depuis l’extérieur, c’est-à-dire via Internet ou un réseau.
Pour cela, il est nécessaire de comprendre comment fonctionne l’accès à une machine à partir d’une URL, par exemple :
Des serveurs DNS (Domain Name System) assurent la correspondance entre les noms de domaine et des adresses IP, ces dernières étant difficilement mémorisables pour un utilisateur.
Les adresses IP pointent vers ce que l’on appelle, selon les cas, un serveur, un load balancer, un cluster ou une machine virtuelle. En simplifiant, il s’agit d’une adresse publique permettant d’atteindre votre service.
Enfin, la machine ciblée doit autoriser les connexions sur certains ports réseau : par défaut, ceux-ci sont fermés et doivent être explicitement ouverts.
Quand vous tapez une URL :
https://frontend-conception-logicielle.kub.sspcloud.frle déroulement est :
- votre ordinateur envoie une demande : « Quelle est l’IP de ce nom ? »
- la demande est envoyée au DNS récursif configuré localement
- ce DNS contacte successivement :
- les serveurs racine ;
- les serveurs du TLD
.fr; - les serveurs autoritaires de
sspcloud.fr;
- il récupère l’IP finale ;
- il vous la renvoie ;
- votre navigateur peut ouvrir la connexion réseau.
Comment savoir quel DNS votre machine utilise ?
Sur macOS / Linux :
scutil --dnsEn résumé#
Une fois l’application installée, elle doit être accessible aux utilisateurs via le réseau.
Cela implique :
- la configuration d’un serveur applicatif (par exemple Uvicorn pour une API Python) ou d’un serveur web statique (dans ce cours, nous utiliserons Vite pour simplifier) ;
- l’attribution d’une adresse IP publique ;
- l’ouverture des ports nécessaires afin d’autoriser la communication avec les clients.
Les actions évoquées juste avant, ne concernent pas directement le code de l’application, mais relèvent de l’environnement d’exécution et de sa configuration réseau; on parle parfois, par extension, de pare-feu applicatif.
D’autres problématiques apparaissent quand on déploie réellement une application pour des utilisateurs, telles que la scalabilité, le routage avancé ou la haute disponibilité.
Préambule : différentes formes d’hébergement#

Historiquement, on distingue plusieurs grandes formes d’hébergement applicatif :
Bare metal : exécution directe sur un serveur physique, sans couche de virtualisation. Cette approche est performante, mais souvent plus complexe à administrer.
Machine virtuelle (VM) : utilisation d’un hyperviseur (par exemple VMware ou KVM) pour exécuter plusieurs systèmes isolés sur une même machine physique.
Conteneur : exécution légère et isolée d’applications via des outils comme Docker ou Kubernetes, partageant le noyau du système d’exploitation hôte.
Idée générale#
L’objectif, au fil du temps, a été de réduire le nombre de machines physiques nécessaires et d’optimiser l’utilisation des ressources, en faisant cohabiter plusieurs traitements sur une même infrastructure grâce à des mécanismes d’isolation des processus.
Tous ces modes d’hébergement restent pertinents selon le contexte : contraintes de performance, coûts, sécurité, simplicité d’exploitation ou exigences réglementaires.
Architecture de Kubernetes : un standard pour l’hébergement cloud#

Kubernetes est une plateforme d’orchestration de conteneurs conçue pour administrer un ensemble de serveurs hébergeant des applications sous forme de conteneurs.
Il fournit une couche d’abstraction permettant de gérer automatiquement le déploiement, l’exécution et l’exploitation d’applications distribuées à l’échelle d’un cluster.
Kubernetes permet notamment :
- de lancer automatiquement des conteneurs sur différentes machines selon les besoins ;
- de conserver les données grâce à des espaces de stockage persistants ;
- de faire communiquer les applications entre elles à l’intérieur du cluster, même si elles sont isolées dans des conteneurs ;
- de gérer le placement des applications, leur redémarrage en cas de problème et leur mise à jour sans interruption visible pour les utilisateurs.
L’idée fondamentale est la suivante :
- partir du concept de processus isolés exécutés sur une machine (via les conteneurs) ;
- administrer plusieurs serveurs réunis au sein d’un même cluster ;
- centraliser la gestion des demandes au niveau du plan de contrôle (control plane) et répartir l’exécution sur les nœuds de travail (worker nodes) ;
- surveiller en continu l’état du cluster afin de garantir que l’état réel corresponde à l’état désiré (nombre de réplicas, services actifs, version des applications, etc.).
Utilisation d’un cluster Kubernetes#
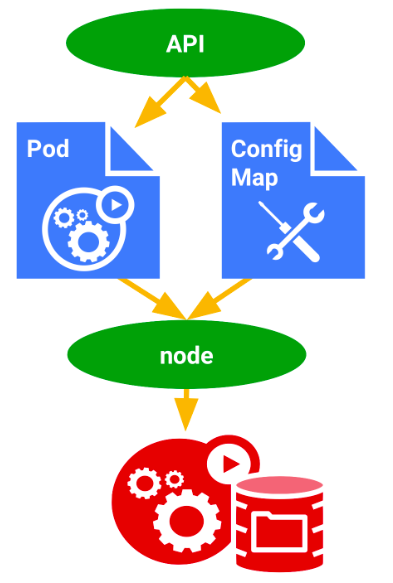
Pour utiliser Kubernetes, on ne se connecte pas directement aux machines. On communique avec un composant central appelé API Server. L’API Server est une interface qui reçoit des demandes (par exemple : « lance cette application », « expose ce service », « ajoute cette configuration ») sous forme de fichiers décrivant ce que l’on veut obtenir dans le cluster.
Ces fichiers sont écrits dans un format lisible par l’humain : YAML (basé sur JSON).
Dans ce cours, nous utiliserons principalement l’outil en ligne de commande kubectl, qui sert d’intermédiaire entre nous et l’API Kubernetes.
Remarque : les outils en ligne de commande (CLI) sont très importants dans l’ingénierie logicielle. On les retrouve partout : administration de bases de données, gestion d’API, déploiement d’applications, etc.
Décrire une application : exemple simple avec un Pod#
Voici un exemple de fichier YAML décrivant un Pod (l’unité de base d’exécution dans Kubernetes) :
apiVersion: v1
kind: Pod
metadata:
name: hello-world-pod
spec:
containers:
- name: hello-world-container
image: ragatzino/backend-demo-conception-logicielle:latest
ports:
- containerPort: 8000Ce fichier décrit ce que Kubernetes doit lancer : un conteneur, à partir d’une image donnée, avec un port ouvert.
Quand on envoie ce fichier au cluster, Kubernetes démarre automatiquement le processus sur l’un des serveurs disponibles.
Déployer via l’API Kubernetes#
Kubernetes permet d’installer des applications à la demande grâce à son API.
On ne déploie pas directement des programmes, mais des ressources Kubernetes, par exemple :
- des Deployments: pour gérer des applications;
- des Services ou Ingress: pour exposer des applications sur le réseau;
- des ConfigMaps : pour stocker de la configuration.
Comme toute API bien constituée, elle nécessite une authentification et n’est pas forcément accessible partout.
Exemples d’implémentations#
Kubernetes est un projet open source, ce qui explique qu’il existe de nombreuses plateformes qui l’utilisent.
Plateformes cloud grand public
- GKE (Google Cloud Platform) : offre Kubernetes chez Google (avec souvent du crédit gratuit au départ)
- EKS : Kubernetes chez Amazon Web Services
- AKS : Kubernetes chez Microsoft Azure
Clouds institutionnels (France)
- SSPCloud : Cloud administré par la division innovation à l’INSEE
- Nubo : cloud interministériel (DGFiP notamment)
Kubectl : Utilitaire CLI pour dialoguer avec l’API server d’un cluster Kubernetes#
kubectl est la commande qui permet de discuter avec l’API Server du cluster.
Il permet de gérer les ressources Kubernetes (Pods, Services, Deployments, etc.), déployer des applications et diagnostiquer des problèmes.
L’installation est disponible ici : https://kubernetes.io/docs/reference/kubectl/
Dans certains environnements (comme SSPCloud), tout est déjà installé et configuré.
Commandes de base à connaître#
Pour afficher les ressources existantes d’un certain type ainsi que leur état :
kubectl get <ressources>où <ressources> peut être par exemple pods, services, deployments ou configmaps.
Pour supprimer une ressource précise :
kubectl delete <ressource> <nom-de-la-ressource><nom-de-la-ressource> correspond simplement au nom attribué à cette ressource dans le cluster.
Pour obtenir des informations détaillées sur une ressource :
kubectl describe <ressource> <nom-de-la-ressource>Cette commande est très utile pour comprendre le comportement d’un Pod ou diagnostiquer un problème de déploiement.
Appliquer une configuration depuis un fichier
Pour envoyer un fichier YAML au cluster :
kubectl apply -f <nom_du_fichier.yaml>Pour supprimer ce qui est décrit dans ce fichier :
kubectl delete -f <nom_du_fichier.yaml>Exemple : un Deployment simple
apiVersion: apps/v1
kind: Deployment
metadata:
name: backend
spec:
selector:
matchLabels:
app: backend
template:
metadata:
labels:
app: backend
spec:
containers:
- name: backend
image: ragatzino/backend-demo-conception-logicielle:latest
resources:
limits:
memory: "200Mi"
cpu: "300m"
envFrom:
- configMapRef:
name: configuration-backend
ports:
- containerPort: 8000Ce fichier demande à Kubernetes de maintenir une application backend en fonctionnement, avec des limites de ressources et de la configuration externe.
Ressources d’un cluster Kubernetes#
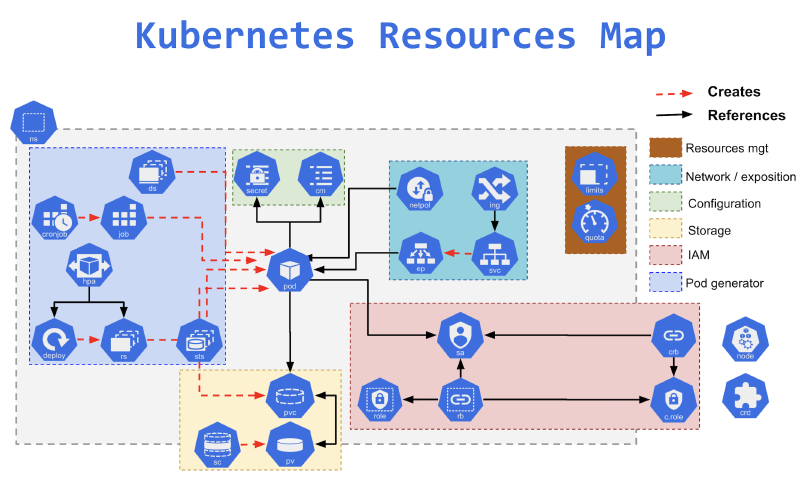
Dans cette section, nous allons présenter plusieurs types de ressources Kubernetes couramment utilisées sur un cluster. Il en existe bien d’autres, chacune répondant à des besoins spécifiques.
Parmi les principales catégories :
- Gestion de la résilience et de l’ordonnancement :
Deployment,StatefulSet,CronJob - Configuration applicative :
ConfigMap,Secret - Routage réseau :
Service,Ingress - Gestion des droits d’accès :
Role,RoleBinding,ServiceAccount - Persistance des données :
PersistentVolume,PersistentVolumeClaim
Remarque : l’écosystème Kubernetes est très vaste et propose une grande diversité de ressources.
Objectif du cours#
Notre but est de déployer une application dans le cloud :
- accessible via une URL fixe ;
- configurable à l’aide de variables d’environnement.
Ressources utilisées dans le cadre du cours#
Afin de rester concentrés sur l’essentiel, nous nous limiterons à quatre ressources :
- Deployment : lancer des Pods, gérer leur réplication et définir une stratégie de mise à jour.
- Service : exposer des Pods à l’intérieur du cluster et leur fournir une adresse réseau stable.
- Ingress : rendre l’application accessible depuis l’extérieur via HTTP et un nom de domaine.
- ConfigMap et Secret : stocker de la configuration et injecter des variables d’environnement dans les conteneurs.
Ces ressources seront détaillées dans la suite de cette partie.
Pour aller plus loin
Pour une introduction complète aux concepts Kubernetes, voir : https://kubernetes.io/docs/concepts/
Pod : la brique élémentaire#
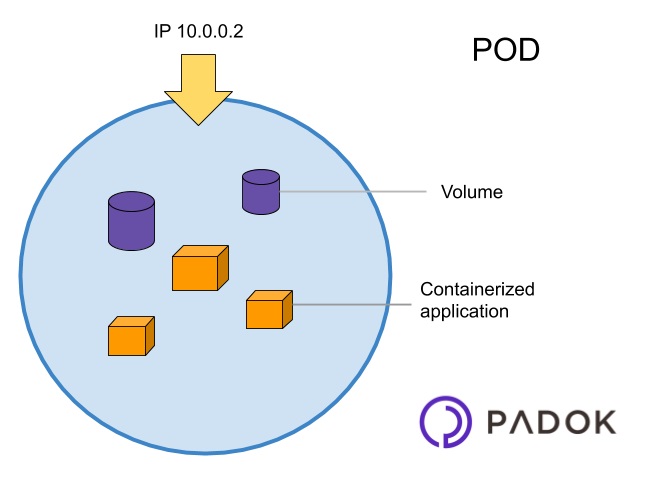
Le Pod constitue l’unité de base de Kubernetes. Il correspond à un ensemble de conteneurs (souvent un seul) qui s’exécutent ensemble et partagent certaines ressources, notamment le réseau.
Dans notre cas, chaque Pod contiendra un seul conteneur. Il pourra donc être assimilé à une instance de l’application, comparable à une commande docker run.
Limite
Si le processus s’arrête brutalement, il ne sera pas redémarré automatiquement. C’est pourquoi on utilise rarement un Pod isolé en production.
Principe
Il est nécessaire d’orchestrer ces traitements et de définir leur comportement en fonction de leur rôle :
- Un traitement asynchrone ponctuel (batch) doit s’exécuter une fois, sans être relancé indéfiniment.
- Un service exposé aux utilisateurs (API, interface web) doit rester disponible en permanence et être automatiquement redémarré en cas de panne.
Deployment : orchestration des Pods#

Un Deployment est une ressource Kubernetes permettant de décrire de façon déclarative l’état souhaité d’un ensemble de Pods.
Il assure notamment :
- la haute disponibilité et l’auto-réparation ;
- le passage à l’échelle (scaling) ;
- les mises à jour progressives et les retours arrière (rollback).
Service : exposition interne et répartition de charge#
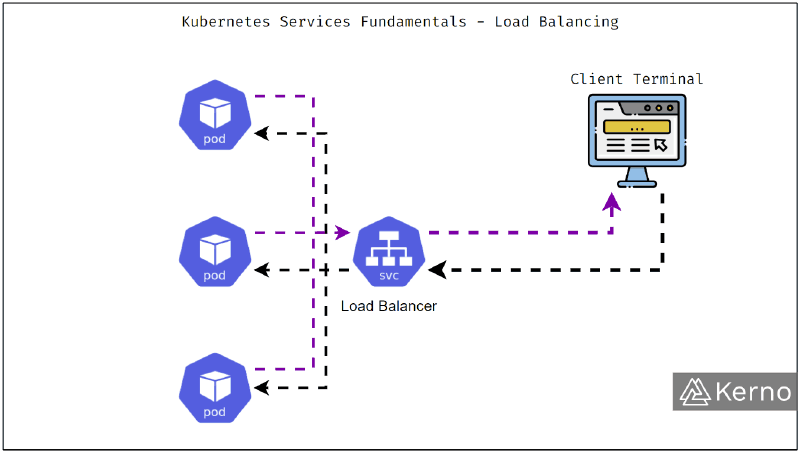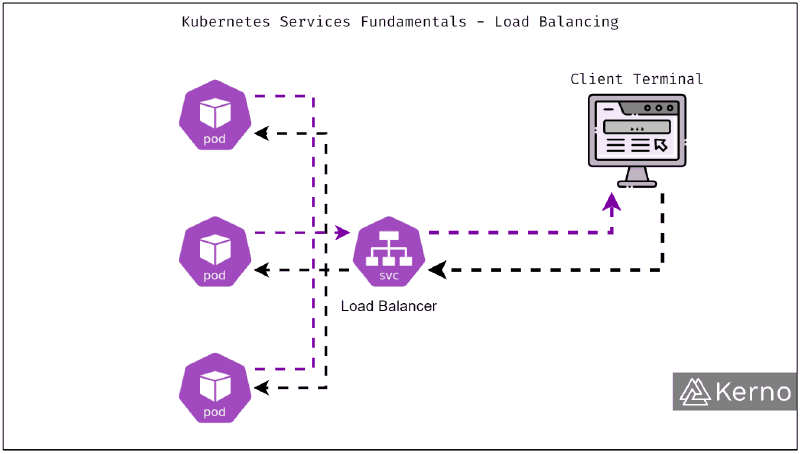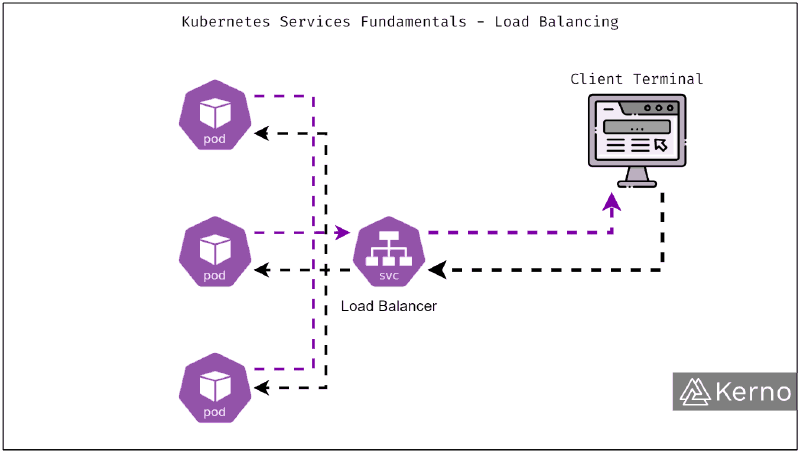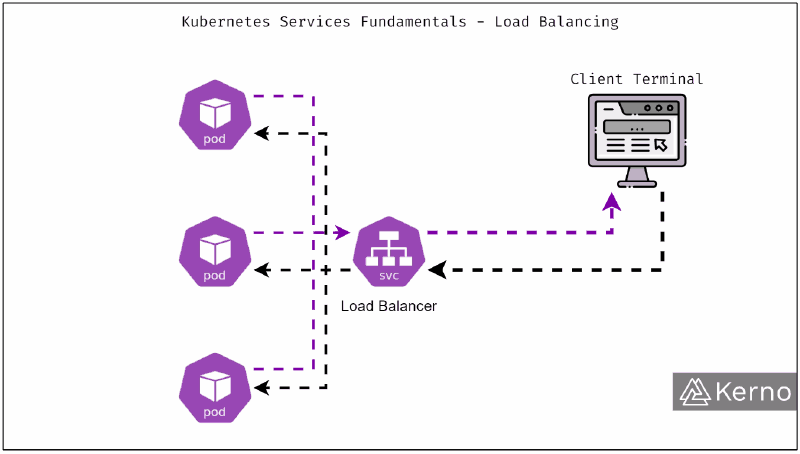
Un Service fournit un point d’accès stable vers un ensemble de Pods et assure la communication interne ainsi que la répartition du trafic.
Exemple :
apiVersion: v1
kind: Service
metadata:
name: application
spec:
selector:
app: application # doit correspondre à un label défini dans le Deployment
ports:
- port: 80 # port exposé côté Service / Ingress
targetPort: 5173 # port du serveur dans le conteneurIngress : exposition HTTP vers l’extérieur#
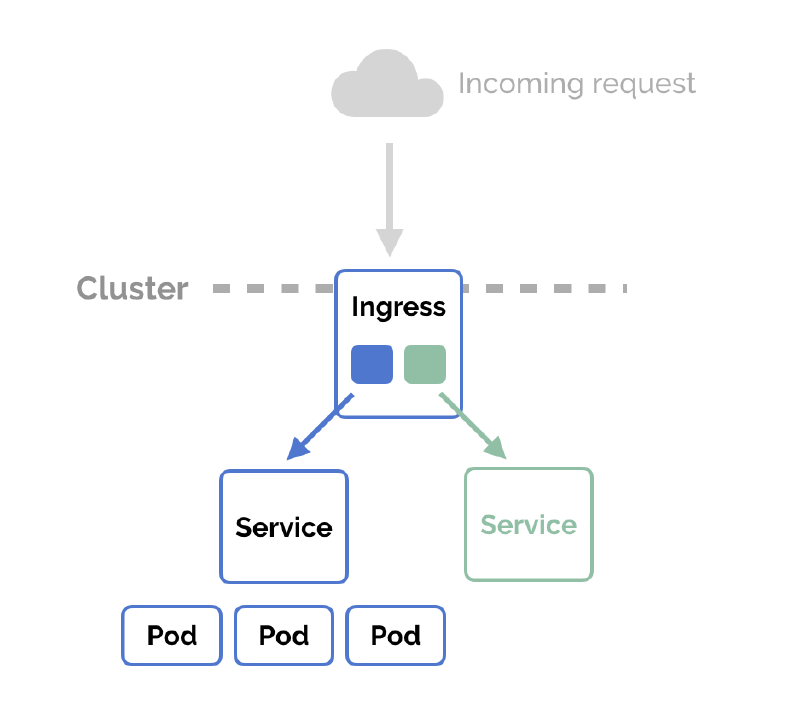
Un Ingress permet de publier un ou plusieurs Services en HTTP/S à l’aide de règles de routage basées sur le nom de domaine et le chemin.
Exemple :
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: application
labels:
name: application
spec:
rules:
- host: hello.kube.sspcloud.fr
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: application
port:
number: 80Remarque : le champ
hostdoit être unique. Si l’URL est déjà utilisée, il faudra en choisir une autre, par exemplemon-application.kub.sspcloud.fr.
L’Ingress nécessite la présence d’un Ingress Controller (comme Nginx Ingress Controller) pour fonctionner. Celui-ci est déjà installé sur la plateforme SSP Cloud.
ConfigMap et Secret : externalisation de la configuration#
Les ConfigMaps et les Secrets permettent d’externaliser la configuration d’une application afin d’éviter de la figer dans les images de conteneurs.
Un ConfigMap est destiné aux paramètres non sensibles (URLs, ports, options applicatives, niveaux de log).
Un Secret est réservé aux données confidentielles telles que les mots de passe, clés API, tokens ou certificats TLS. Les valeurs y sont encodées en base64 dans les manifestes YAML (ce qui ne constitue pas un chiffrement) et leur accès est généralement plus restreint.
Règle pratique :
- Donnée sensible → Secret
- Donnée non sensible → ConfigMap
Exemple de ConfigMap#
Un ConfigMap stocke des données de configuration sous forme de paires clé–valeur et peut être injecté dans les Pods.
apiVersion: v1
kind: ConfigMap
metadata:
name: configuration-application
data:
VARIABLE_ENVIRONNEMENT1: variable_environnement
DATABASE_URL: "postgres://user:password@db:5432/mydb"Ces données peuvent ensuite être exposées dans un conteneur sous forme de variables d’environnement :
containers:
- name: mon-container
image: mon-image:v1
envFrom:
- configMapRef:
name: mon-configmapExemple de Secret#
Un Secret permet de stocker des données sensibles (mots de passe, tokens, clés…) et de les injecter dans les Pods de la même manière qu’un ConfigMap.
Valeurs originales :
- token :
my-secret-token
Encodage en base64 :
echo -n "my-secret-token" | base64Le -n évite d’ajouter un retour à la ligne, ce qui est important pour Kubernetes.
Puis dans le manifeste :
apiVersion: v1
kind: Secret
metadata:
name: credentials-application
type: Opaque
data:
DATABASE_PASSWORD: cGFzc3dvcmQ=
API_TOKEN: bXktc2VjcmV0LXRva2VuInjection dans un conteneur :
containers:
- name: mon-container
image: mon-image:v1
envFrom:
- secretRef:
name: credentials-applicationDe la même manière que pour le fichier
.env.local, nous ne souhaitons pas versionner le fichier contenant les secrets dans notre dépôt Git. Il ne devra donc pas être committé et devra être ajouté au fichier.gitignore. En revanche, nous pouvons fournir un fichiersecret.yaml.templatedécrivant exactement la structure attendue du manifeste, mais avec des valeurs vides ou factices. Le fichierREADMEdevra alors expliquer comment compléter ces valeurs avant déploiement.
À l’Insee, afin que les mots de passe n’apparaissent pas en clair, les Secrets sont complétés par un gestionnaire externe : Vault. Dans notre fichier de Secret, nous faisons directement référence à l’emplacement de la ressource Vault où se trouve la valeur confidentielle.
TP : Déploiement d’une application sur les plateformes Kubernetes du SSP Cloud#
Ce TP nécessite la production d’une image Docker et son déploiement sur un registre public (par exemple Docker Hub) afin de pouvoir l’utiliser ensuite sur le cluster.
Le SSP Cloud met à disposition de ses utilisateurs un API Server Kubernetes accessible depuis les services hébergés à l’intérieur du cluster. Cette plateforme est proposée avec un niveau de support limité : elle est destinée aux preuves de concept (PoC), ne doit pas héberger de données sensibles et ne fournit pas de garantie de service. Elle est toutefois parfaitement adaptée aux expérimentations et à l’hébergement de projets pédagogiques de l’ENSAI.
Pour interagir avec le cluster, il est nécessaire d’utiliser un service qui y est lui-même déployé, l’API Kubernetes n’étant accessible que depuis l’intérieur du cluster.
Le SSP Cloud propose plusieurs services permettant d’instancier des environnements de travail, notamment des plateformes de développement :
- VS Code
- RStudio
1 — Mise en place d’un service dans le cluster#
Rendez-vous sur le SSP Cloud et déployez un service vscode-python en sélectionnant le rôle admin dans l’onglet Role.
Ce rôle donne au service VS Code les permissions nécessaires pour déployer des ressources dans le cluster Kubernetes du SSP Cloud.
2 — Interaction avec le cluster Kubernetes#
Une fois VS Code lancé, ouvrez-le puis démarrez un terminal. Nous utiliserons l’outil en ligne de commande kubectl.
Exécutez la commande suivante :
kubectl get podsVous constaterez que vous disposez déjà d’une ressource de type Pod : il s’agit du service VS Code dans lequel vous êtes connecté.
3 — Récupération des manifestes de base#
Pour vous aider, des fichiers exemples sont fournis dans le dépôt du cours : https://github.com/conception-logicielle-ensai/exemples-cours/tree/main/kubernetes/app
Clonez le projet :
git clone https://github.com/conception-logicielle-ensai/exemples-cours.gitExplorez ensuite le dossier :
exemples-cours/kubernetes/appIl contient plusieurs fichiers YAML correspondant aux manifestes de ressources Kubernetes.
Commencez par appliquer la configuration :
kubectl apply -f exemples-cours/kubernetes/app/configmap.yamlPuis déployez l’application :
kubectl apply -f exemples-cours/kubernetes/app/deployment.yamlVérifiez que les Pods sont bien créés :
kubectl get pods4 — Exposition sur Internet#
Modifiez le manifeste Ingress afin d’y définir une URL qui vous est propre, puis appliquez les ressources suivantes.
Service :
kubectl apply -f exemples-cours/kubernetes/app/service.yamlIngress :
kubectl apply -f exemples-cours/kubernetes/app/ingress.yaml5 — Modification de la configuration et redémarrage#
Nous allons maintenant modifier la configuration afin d’afficher une autre information sur la page d’accueil de Swagger.
Dans le ConfigMap, il est possible de définir des variables d’environnement utilisées par l’application.
Celle-ci lit notamment la variable APP_TITLE, qui permet de modifier le titre affiché dans la documentation Swagger.
Ajoutez cette variable et sa valeur dans le ConfigMap.
Appliquez ensuite la modification :
kubectl apply -f exemples-cours/kubernetes/app/configmap.yamlLes variables d’environnement n’étant prises en compte qu’au démarrage, il est nécessaire de redémarrer les Pods.
Deux possibilités :
Option 1 — Redéployer toutes les ressources :
kubectl delete -f exemples-cours/kubernetes/app/
kubectl apply -f exemples-cours/kubernetes/app/Option 2 — Supprimer un Pod pour forcer sa recréation :
kubectl get pods
kubectl delete pod <nom-du-pod>6 — Déploiement de votre propre application#
Modifiez l’image Docker ainsi que, si nécessaire, les ports exposés dans les manifestes Deployment et Service afin de déployer l’application que vous avez packagée précédemment dans ce TP.
Vous pouvez également vous inspirer de l’exemple suivant : https://github.com/conception-logicielle-ensai/archi-exemple/tree/main/kubernetes
Si, par la suite, vous modifiez votre image Docker sur Docker Hub, il sera nécessaire de relancer le déploiement afin que ces changements soient pris en compte (puisque le tag latest est utilisé dans le manifeste). Vous pouvez pour cela redéployer la ressource avec la commande suivante :
kubectl rollout restart deployment <mon-application>avec <mon-application> le nom que vous avez donnez à votre deployement