
Accès aux exemples
Les exemples présentés sont accessibles directement sur le dépôt git associé : https://github.com/conception-logicielle-ensai/exemples-cours/tree/main/
Dans cette partie, on va voir ce qu’est un web service, pourquoi on en utilise et comment en construire un en Python.
Préambule : Script vs Application#
On a pu distinguer dans le module architecture logicielle, un code interpreté, d’un code compilé. Ce n’est pas la seule distinction entre un code.
Maintenant, voyons la différence entre un script et une application, deux types de programmes qui ont des usages distincts :
- Les scripts : ce sont des programmes conçus pour effectuer une tâche précise et ponctuelle. Ils ont pour objectif d’être executés sur une durée définie.
Ils sont généralement exécutés par des langages interprétés comme Python, R, bash, javascript …
Un script peut être lancé plusieurs fois, mais dans ce cas, on parle d’un batch : on l’exécute à intervalle régulier, il fait son travail, puis s’arrête.
- Les applications : elles sont conçues pour fonctionner en continu, tant qu’on ne les arrête pas. Elles sont souvent plus complexes et à l’origine, elles étaient développées en langages compilés (comme
JavaouC++), mais aujourd’hui, ce n’est plus forcément le cas.
Applications et architectures applicatives#
Une application est un programme conçu pour répondre à des demandes et fournir un service. Selon la manière dont elles sont conçues, on distingue plusieurs types d’applications :
Applications “client lourd” : elles sont entièrement installées sur un ordinateur ou un appareil, et exécutent toutes leurs fonctionnalités en local.
Exemple : le logiciel interne d’une machine à café.Applications “client / serveur” : elles sont partiellement installées sur l’ordinateur de l’utilisateur, mais communiquent avec un serveur distant pour accéder aux données ou exécuter certaines tâches.
Exemple : l’outil Git en ligne de commande, qui envoie et récupère des fichiers depuis un serveur distant.
Ce modèle client / serveur est largement utilisé, car il simplifie la gestion des mises à jour : une seule mise à jour sur le serveur suffit pour que tous les utilisateurs en bénéficient. De plus, les données sont centralisées, ce qui évite les pertes d’information dispersées sur plusieurs appareils.
- Applications “n-tiers” : elles suivent le principe du client / serveur, mais avec plusieurs couches intermédiaires pour mieux répartir les traitements.
Exemple : SNCF Connect, qui repose sur plusieurs services interconnectés.
Où se place un Web Service ?#
Un web service repose au minimum sur une architecture client / serveur, mais il peut aussi s’intégrer dans une architecture n-tiers si nécessaire. Son rôle est de fournir un service accessible à distance, permettant à différentes applications de communiquer entre elles.
Voici comment ça fonctionne :
- Un client (site web, application, script…) envoie une requête au serveur dans un format standard : XML, JSON ou HTTP.
- Cette requête est transmise au serveur via un protocole comme SOAP, REST ou HTTP.
- Le serveur traite la demande et répond dans le même format : XML, JSON ou HTTP.
En résumé, un web service est un moyen de connecter des applications entre elles, en utilisant une communication standardisée.
Protocole HTTP#
Protocoles de communication#
Pour qu’une communication puisse avoir lieu entre deux machines sur un réseau, il faut suivre un ensemble de règles, appelées protocoles.
Les deux protocoles fondamentaux utilisés pour la transmission des données sont :
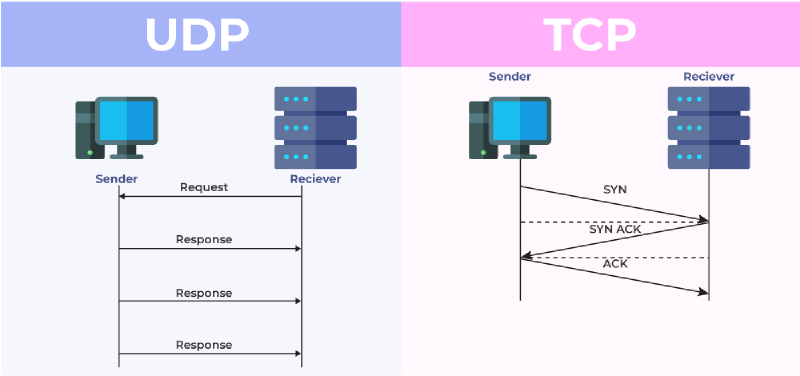
- TCP (Transmission Control Protocol) : permet un échange de données fiable et contrôlé. Chaque paquet envoyé est vérifié, garantissant une transmission sans erreur. Il y a donc un aspect transactionnel, l’échange de données est considéré complet lorsque les derniers bit émis le signalent.
- UDP (User Datagram Protocol) : plus rapide mais moins sécurisé, il ne vérifie pas la bonne réception des paquets, ce qui peut entraîner des pertes d’informations. Les données sont envoyées de manière brut. Ce protocole est couramment utilisé pour le streaming de contenus audio et vidéo.
HTTP et transmission des données#
Le protocole HTTP (HyperText Transfer Protocol) est un protocole de niveau supérieur basé sur TCP. Il permet l’échange de ressources (pages web, API, fichiers…) entre un client et un serveur.
Un client peut envoyer des requêtes HTTP au serveur sur :
- Le port 80 pour des connexions HTTP classiques.
- Le port 443 pour des connexions sécurisées en HTTPS (nécessitant des certificats de chiffrement).
Pour aller plus loin
Client HTTP - Quelques rappels#
Un client HTTP est un programme ou une bibliothèque capable d’envoyer des requêtes HTTP à un serveur pour récupérer des informations ou effectuer des actions.
Exemples de clients HTTP#
- Navigateurs web : Chrome, Firefox, Edge…
- Outils en ligne de commande :
curl,httpie… - Bibliothèques de programmation :
requestsen Python,axiosen JavaScript…
Ces clients peuvent envoyer plusieurs types de requêtes, appelées méthodes HTTP :
| Méthode | Description |
|---|---|
| GET | Récupère une ressource depuis le serveur. |
| POST | Envoie des données pour créer une nouvelle ressource. |
| PUT | Ajoute ou met à jour une ressource sur le serveur. |
| DELETE | Supprime une ressource si elle existe. |
Requête HTTP - Structure d’une requête HTTP#
Une requête HTTP comprend trois éléments principaux :
Une ligne de requête
- La méthode (ex :
GET) - L’URL de la ressource demandée
- La version du protocole HTTP
- La méthode (ex :
Des en-têtes HTTP
- Métadonnées sur la requête (type de contenu, authentification…)
Un corps de message (facultatif)
- Contenu de la requête, souvent en JSON ou XML
Exemple d’envoi d’une requête avec curl en ligne de commande :
curl http://localhost:8000Exemple en Python avec requests :
import requests
response = requests.get("http://google.com")
print(response.status_code) # Affiche le code de statut
# print(response.json()) # Si la réponse est en JSON
# print(response.text) # Si la réponse est en texte brutPour aller plus loin
Le client léger qu’on préconise pour python c’est requests, on retrouve la doc ici : Faire une requête avec le module requests
Pour aller plus loin
Souvent, les requêtes Curl sont fournies dans la documentation Swagger pour accéder aux services. Le site Curlconverter permet de convertir ces requêtes Curl en requêtes dans le langage de votre choix. Cela peut être utile si vous devez interagir avec une API externe dans votre programme.
Requête HTTP - Structure d’une réponse HTTP#
Une réponse HTTP contient :
- Une ligne de statut (ex :
200 OK,404 Not Found) - Des en-têtes HTTP (type de contenu, encodage…)
- Un corps de message (souvent un fichier HTML ou JSON)
Les différents codes retours :
- Code retours
2XX:200,201… - La requête s’est bien passée et elle a eu un effet dans le système. - Code retours
3XX:300,301,302… - La requête est entrée dans le système et a été redirigée. - Code retours
4XX:400,401,402,403,404… => La requête a été rejetée par le système car l’utilisateur de l’API n’a pas effectué une action valide. (non authentifié, demande de ressources non présentes) - Code retours
5XX:500,502- La requête a été rejetée par l’application pour des raisons internes au système : plantage interne, le serveur n’était pas prêt, etc…
Les navigateurs web sont des clients HTTP qui envoient des requêtes GET lorsqu’on navigue sur une page et POST lorsqu’on soumet un formulaire.
Bonnes pratiques
Il est utile d’implémenter des codes de réponse HTTP pertinents dans vos applications pour faciliter le diagnostic des erreurs et l’interaction avec les clients.
Requête HTTP : Gestion des identités et session#
Parfois pour accéder il est nécessaire de s’authentifier, cela se fait en général avec une en-tête (un Header) dédié : Authorization: <type> <credentials>.
1. Authentification basique (Basic Auth)#
La méthode la plus simple repose sur un couple utilisateur / mot de passe.
L’authentification Basic Auth consiste à :
- Concaténer l’identifiant et le mot de passe sous la forme :
username:passwordEncoder cette chaîne en Base64
Envoyer le résultat dans l’en-tête HTTP :
Authorization: Basic <base64(username:password)>Exemple avec curl
curl -X GET https://api.exemple.com/api/books \
-H "Authorization: Basic YWxpY2U6c2VjcmV0MTIz"À noter :
curlsait aussi gérer automatiquement le header Basic Auth :
curl -u alice:secret123 https://api.exemple.com/api/books2. Authentification par jeton (Token-based authentication)#
Aujourd’hui, on utilise majoritairement des jetons à durée de vie limitée.
Exemple avec un Bearer Token
L’authentification par jeton repose sur les étapes suivantes :
- L’utilisateur s’authentifie une première fois (login / OAuth / SSO, etc.).
- Le serveur d’authentification émet un jeton signé, généralement à durée de vie limitée.
- Le client stocke ce jeton.
- Le jeton est transmis à chaque requête dans l’en-tête HTTP :
Authorization: Bearer <token>Exemple concret
- Authentification initiale (login)
Requête :
POST /auth/login HTTP/1.1
Host: api.exemple.com
Content-Type: application/json
{
"username": "alice",
"password": "secret123"
}Réponse du serveur :
HTTP/1.1 200 OK
Content-Type: application/json
{
"access_token": "eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9...",
"token_type": "Bearer",
"expires_in": 3600
}- Utilisation du jeton pour accéder à une ressource protégée
GET /api/books HTTP/1.1
Host: api.exemple.com
Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9...Remarque : Le jeton expire, il faut donc avoir des mécanismes en place pour surveiller la date d’expiration et le renouveler.
3. Gestion de sessions#
Dans les applications clientes (API consumer, micro-services, scripts métiers), il est courant de centraliser la gestion de l’authentification HTTP au sein d’une session dédiée, plutôt que de manipuler directement les headers et les jetons dans chaque appel. L’objectifs de cette approche est d’éviter la duplication du code d’authentification et séparer les préoccupations (authentification vs logique métier).
- Une session HTTP est créée avec :
- une URL de base
- un access token
- un refresh token
- Chaque requête utilise automatiquement le jeton courant
- En cas de réponse
401 Unauthorized:- le jeton access token est rafraîchi en utilisant le refresh token
- la requête est rejouée
- Le reste de l’application n’a aucune connaissance de ces mécanismes
Exemple d’implémentation
import requests
from typing import Any
class HttpSession:
"""
Wrapper de session HTTP gérant automatiquement l'authentification
et le rafraîchissement des jetons.
"""
def __init__(self, base_url: str, access_token: str, refresh_token: str):
self.base_url = base_url
self.access_token = access_token
self.refresh_token = refresh_token
self.session = requests.Session()
def _auth_headers(self) -> dict:
"""
Génère les headers d'authentification pour les requêtes sortantes.
"""
return {
"Authorization": f"Bearer {self.access_token}"
}
def refresh_access_token(self) -> None:
"""
Rafraîchit l'access token à l'aide du refresh token.
"""
response = self.session.post(
f"{self.base_url}/auth/refresh",
json={"refresh_token": self.refresh_token}
)
response.raise_for_status()
data = response.json()
self.access_token = data["access_token"]
def get(self, path: str, **kwargs) -> Any:
"""
Exécute une requête GET authentifiée avec gestion automatique
de l'expiration du jeton.
"""
response = self.session.get(
f"{self.base_url}{path}",
headers=self._auth_headers(),
**kwargs
)
if response.status_code == 401:
self.refresh_access_token()
response = self.session.get(
f"{self.base_url}{path}",
headers=self._auth_headers(),
**kwargs
)
response.raise_for_status()
return response.json()class BookService:
def __init__(self, http_session: HttpSession):
self.http = http_session
def list_books(self):
return self.http.get("/api/books")session = HttpSession(
base_url="https://api.exemple.com",
access_token="eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9...",
refresh_token="def50200a1b2c3..."
)
book_service = BookService(session)
books = book_service.list_books()Les API : une forme de Web Service#
Définition de la CNIL (Commission Nationale de l’Informatique et des Libertés) d’une API :
Une API (Application Programming Interface ou « Interface de Programmation d’Application ») est une interface logicielle qui permet de « connecter » un logiciel ou un service à un autre logiciel ou service afin d’échanger des données et des fonctionnalités.
Les API offrent de nombreuses possibilités, comme la portabilité des données, la mise en place de campagnes de courriels publicitaires, des programmes d’affiliation, l’intégration de fonctionnalités d’un site sur un autre ou l’open data. Elles peuvent être gratuites ou payantes.
Quel est l’Intérêt des API ?#
Objectif :
Diffuser des données et des services à destination d’autres applications.
Pour mieux comprendre :
Voici la réponse d’une application de type IHM (Interface Homme-Machine) :
<li class="list__item">
<a class="block__link block__link_img" href="/270229/evt.htm">
<picture>
<source
media="(min-width: 650px)"
srcset="/zg/r115-165-0/vz-F46C96DB-9F48-44B1-9297-A85CBDD9FF1B.jpeg"
/>
<source
media="(max-width: 649px)"
srcset="/zg/r115-165-0/vz-F46C96DB-9F48-44B1-9297-A85CBDD9FF1B.jpeg"
/>
<img
class="pub__img"
alt="Apollo World Live en live streaming Apollo Théâtre - Salle Apollo 360"
title="Apollo World Live en live streaming Apollo Théâtre - Salle Apollo 360"
src="/zg/r115-165-0/vz-F46C96DB-9F48-44B1-9297-A85CBDD9FF1B.jpeg"
/>
<div class="block__offers-container">
<span class="block__offers block__offers_price">
<span class="text__mini">À partir de</span> 10€
</span>
</div>
</picture>
</a>
<a href="/270229/evt.htm" class="block__link block__link_title">
<span>
<b style="color:#1A2E41">Apollo World Live en live streaming</b>
</span>
</a>
</li>
<li class="list__item">
<a class="block__link block__link_img" href="/270099/evt.htm">
<picture>
<source
media="(min-width: 650px)"
srcset="/zg/r115-165-0/vz-0196DA94-7B3F-4164-B114-6B54405395ED.jpeg"
/>
<source
media="(max-width: 649px)"
srcset="/zg/r115-165-0/vz-0196DA94-7B3F-4164-B114-6B54405395ED.jpeg"
/>
<img
class="pub__img"
alt="Impro Visio en Live Streaming My Digital Arena"
title="Impro Visio en Live Streaming My Digital Arena"
src="/zg/r115-165-0/vz-0196DA94-7B3F-4164-B114-6B54405395ED.jpeg"
/>
<div class="block__offers-container">
<span class="block__offers block__offers_price">
<span class="text__mini">À partir de</span> 12€
</span>
</div>
</picture>
</a>
<a href="/270099/evt.htm" class="block__link block__link_title">
<span>Impro Visio en Live Streaming</span>
</a>
</li>
<li class="list__item">
<a class="block__link block__link_img" href="/269015/evt.htm">
<picture>
<source
media="(min-width: 650px)"
srcset="/zg/r115-165-0/vz-577747CF-85FB-4504-87E8-0B1B585E9324.jpeg"
/>
<source
media="(max-width: 649px)"
srcset="/zg/r115-165-0/vz-577747CF-85FB-4504-87E8-0B1B585E9324.jpeg"
/>
<img
class="pub__img"
alt="Le Roi Lion Théâtre de la Tour Eiffel"
title="Le Roi Lion Théâtre de la Tour Eiffel"
src="/zg/r115-165-0/vz-577747CF-85FB-4504-87E8-0B1B585E9324.jpeg"
/>
<div class="block__offers-container">
<span class="block__offers block__offers_price">
<span class="text__mini">À partir de</span> 23€
</span>
</div>
</picture>
</a>
<a href="/269015/evt.htm" class="block__link block__link_title">
<span>Le Roi Lion</span>
</a>
</li>Et voici la réponse d’une application de type API :
{
"top": [
{
"title": "Apollo World Live en live streaming",
"url": "/270229/evt.htm",
"image": "/zg/r115-165-0/vz-F46C96DB-9F48-44B1-9297-A85CBDD9FF1B.jpeg",
"price": "10€"
},
{
"title": "Impro Visio en Live Streaming",
"url": "/270099/evt.htm",
"image": "/zg/r115-165-0/vz-0196DA94-7B3F-4164-B114-6B54405395ED.jpeg",
"price": "12€"
},
{
"title": "Le Roi Lion",
"url": "/269015/evt.htm",
"image": "/zg/r115-165-0/vz-577747CF-85FB-4504-87E8-0B1B585E9324.jpeg",
"price": "23€"
}
]
}Selon vous, quelle est la réponse la mieux adaptée pour échanger des données ?
Différence entre un site Web et un Web Service :
Site Web : Fournit des données et leur mise en forme (HTML + CSS) pour être lisibles par des humains.
Web Service (dont les API font partie) : Fournit uniquement des données brutes, indépendantes de la présentation, destinées à être exploitées par d’autres applications.
Les API sont également une belle prouesse pour l’interopérabilité des services. En effet, elles répondent à une norme agnostique au langage.
Exemple : si je développe une application pour afficher des prévisions météorologiques, je peux créer mes modèles de Machine Learning en Python et mes régressions en R. En exposant les résultats via deux API au format identique, mon site Web pourra afficher les résultats de manière cohérente, quel que soit le langage utilisé pour les générer.
Comment fonctionne une API ?#
Une API (Interface de Programmation Applicative) permet à différentes applications de communiquer entre elles en exposant des services accessibles via des ressources. Ces services, appelés endpoints, déclenchent l’exécution de fonctions spécifiques lorsqu’un utilisateur en fait la demande. L’API définit donc comment les clients (autres applications ou utilisateurs) peuvent interagir avec elle, en mettant l’accent sur ses fonctionnalités tout en cachant ses détails internes.
En Python, plusieurs frameworks permettent de créer des API web :
- Django : Un framework complet, idéal pour les grands projets. Il intègre des outils prêts à l’emploi pour gérer les bases de données, l’authentification, etc…
- Flask : Plus léger et flexible, il permet de mettre en place rapidement un service HTTP, qu’il soit statique ou une API.
- FastAPI : Plus récent et optimisé, il facilite l’autodocumentation et la gestion des données grâce à la sérialisation et désérialisation.
Une API reçoit des requêtes HTTP et y répond avec des réponses HTTP, qui incluent un code de statut, des en-têtes (headers) et un corps (body).
Les API utilisent le protocole HTTP et retournent des données dans des formats indépendants des langages de programmation.
Les formats les plus courants sont :
- JSON (très utilisé car compatible avec JavaScript, omniprésent sur le web) :
{ "employees": [ { "firstName": "John", "lastName": "Doe" }, { "firstName": "Anna", "lastName": "Smith" }, { "firstName": "Peter", "lastName": "Jones" } ] } - XML (plus courant dans les systèmes anciens) :
<?xml version="1.0" standalone="yes"?> <employees> <employee> <firstName>John</firstName> <lastName>Doe</lastName> </employee> <employee> <firstName>Anna</firstName> <lastName>Smith</lastName> </employee> <employee> <firstName>Peter</firstName> <lastName>Jones</lastName> </employee> </employees>
Les requêtes envoyées à une API sont aussi souvent en JSON ou XML.
Remarque : une fois
pythonisésces formats seront récupérés comme des objets ou des dictionnaires. Mais pour cela il faut parler de sérialisation / désérialisation.
Sérialisation / Désérialisation#
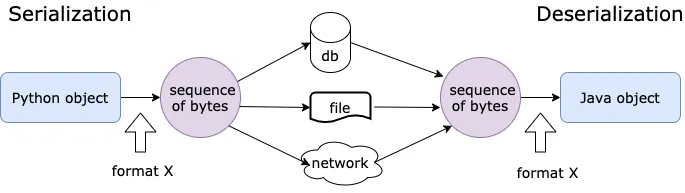
Un des enjeux du travail avec des ressources externes d’un programme est de savoir convertir les entrées d’un programme en des formes connues de notre programme (désérialisation), mais également de pouvoir exposer des objets connus de notre programme dans un format utilisable par d’autres programmes (sérialisation).
faire le pont entre le monde externe (JSON, HTTP, API) et le monde interne du programme (objets, classes).
Exemple : une entité métier User
from dataclasses import dataclass
@dataclass
class User:
name: str
age: int
city: strDésérialisation (JSON → objet)#
json_data = {
"name": "Alice",
"age": 25,
"city": "Paris"
}Conversion vers un objet métier
def user_from_dict(data: dict) -> User:
return User(
name=data["name"],
age=data["age"],
city=data["city"],
)
user = user_from_dict(json.loads(json_data))
print(user.name) # AliceSérialisation (objet → JSON)#
def user_to_dict(user: User) -> dict:
return {
"name": user.name,
"age": user.age,
"city": user.city,
}Encodage JSON
import json
json_string = json.dumps(user_to_dict(user))
print(json_string)Cette logique doit être intégrée dans la conception de vos logiciels : toujours contrôler les entrées et les convertir en un format connu du système.
Par exemple, en programmation orientée objet, il sera attendu qu’entre deux couches de séparation architecturale, vous introduisiez des objets de type DTO (Data Transfer Object). Ainsi, des DTO seront utilisés entre la couche service et DAO, mais aussi entre la couche contrôleur et service. Cela permet une conversion et, par conséquent, de pérenniser le modèle dans chacune des couches de votre système.
Tout cela a déjà été expliqué dans cette partie du cours Bonnes pratiques du développement et design patterns.
Pour aller plus loin
Optimisation : Synchronicité / Asynchronicité#
L’asynchronisme est particulièrement avantageux lorsqu’il s’agit d’effectuer des appels à des services Web, car il permet à votre programme de poursuivre son exécution pendant l’attente des réponses.
Prenons l’exemple d’un programme qui nécessite plusieurs appels à des services Web pour obtenir des données. Si vous procédez de manière synchrone, c’est-à-dire en réalisant les appels un à un dans l’ordre, votre programme devra attendre la réponse de chaque appel avant de continuer : en effet les requêtes HTTP sont des processus synchrones. Cela peut être chronophage, surtout si les réponses mettent du temps à arriver ou que vous multipliez les requêtes à la chaîne.
En revanche, en adoptant une approche asynchrone, vous pouvez envoyer plusieurs appels simultanément sans avoir à attendre la fin de chacun avant de passer au suivant. Ainsi, votre programme peut continuer à s’exécuter pendant que les requêtes sont traitées, et il peut gérer les réponses dès leur arrivée.
Avec Python et la librairie asyncio, dès que vous avez besoin du résultat d’une requête asynchrone, vous pouvez utiliser l’instruction await, qui suspend l’exécution jusqu’à ce que toutes les fonctions asynchrones précédentes soient complètes.
Après cela dépend aussi du serveur du webservice qui doit être capable de gérer plusieurs réponses en parallèle, c’est pour cela qu’on s’appuie sur WSGI plutôt que des serveurs ASGI dans du python moderne.
import asyncio
import aiohttp
async def fetch_data(url):
print(f"Début de la requête : {url}")
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
data = await response.json()
print(f"Données récupérées depuis {url}: {data}")
return data
async def process_data(data1, data2):
print("Traitement des données...")
await asyncio.sleep(1) # Simule un traitement
print(f"Données traitées : {data1} & {data2}")
async def main():
url1 = "https://jsonplaceholder.typicode.com/todos/1"
url2 = "https://jsonplaceholder.typicode.com/todos/2"
# Exécuter les deux requêtes en parallèle
task1 = asyncio.create_task(fetch_data(url1))
task2 = asyncio.create_task(fetch_data(url2))
# Attendre que les deux requêtes soient terminées
data1 = await task1
data2 = await task2
# Traiter les données obtenues
await process_data(data1, data2)
print("Processus terminé !")
asyncio.run(main())Pour aller plus loin
Quelques mots sur FastAPI#
FastAPI est un framework web qui simplifie la création d’API en Python, notamment par une gestion efficace de la sérialisation et de la désérialisation des données.
Il repose sur deux autres frameworks :
Starlettepour les fonctionnalités liées au web.Pydanticpour la gestion des données.
FastAPI est open source et est utilisé par de nombreuses entreprises, telles que Netflix, Uber et Microsoft. Il est très utilisé dans le monde de la datascience.
FastAPI facilite la gestion des requêtes asynchrones.
Installation#
Pour installer FastAPI, utilisez les commandes suivantes :
uv add fastapi
uv add "uvicorn[standard]"Structure d’un projet#
Exemple pratique :#
- Créez un fichier nommé
main.pyavec le contenu suivant :
from pydantic import BaseModel
from fastapi import FastAPI
app = FastAPI()
class Item(BaseModel):
"""
Représente un article avec ses détails.
- **name**: Le nom de l'article.
- **description**: Une description optionnelle de l'article.
- **price**: Le prix de l'article.
- **tax**: Une taxe optionnelle associée à l'article.
- **tags**: Une liste de tags associés à l'article.
"""
name: str
description: str | None = None
price: float
tax: float | None = None
tags: list[str] = []
@app.post("/items/", summary="Créer un article", description="Crée un nouvel article avec les détails fournis.")
async def create_item(item: Item) -> Item:
"""
Crée un nouvel article avec les informations fournies dans le corps de la requête.
- **item**: Détails de l'article à créer.
Renvoie l'article créé.
"""
return item
@app.get("/items/", summary="Lire les articles", description="Récupère une liste d'articles prédéfinis.")
async def read_items() -> list[Item]:
"""
Récupère une liste d'articles prédéfinis.
Renvoie une liste d'articles avec des noms et des prix.
"""
return [
Item(name="Portal Gun", price=42.0),
Item(name="Plumbus", price=32.0),
]- Lancez le serveur avec la commande :
uv run uvicorn main:app --reloadVotre application sera disponible à l’adresse suivante, que vous pouvez ouvrir dans votre navigateur :http://127.0.0.1:8000/
Ressources supplémentaires#
Quelques exemples pour vous permettre de démarrer l’implémentation de vos API :
- Un exemple avec une architecture clean, montrant les possibilités de documentation, ce qui donne un confort d’utilisation aux utilisateurs (valorisé) : consultez cet exemple de définition d’une application FastAPI avec une bonne architecture du code.
- Exemple utilisant les DTO cet exemple sur les DTO du cours, qui illustre les interactions entre les différentes couches de l’application.
Ressources officielles:
- Pour en savoir plus sur FastAPI, lisez la documentation officielle.
- tutoriel realpython : https://realpython.com/fastapi-python-web-apis/
CORS et Middleware d’authentification#
Une API exposée sur le Web doit répondre à deux problématiques distinctes :
Qui a le droit d’appeler l’API depuis un navigateur ? → CORS (Cross-Origin Resource Sharing)
Qui a le droit d’accéder aux ressources métier ? → Authentification / Autorisation
Ces deux notions sont complémentaires mais totalement indépendantes.
CORS Middleware#
Rôle du CORS#
Le CORS permet au navigateur de savoir si une API accepte des requêtes provenant d’une autre origine (domaine, port, protocole).
Tout cela sont des origines différentes:
- http://localhost
- https://localhost
- http://localhost:8080
Le CORS ne protège pas l’API. Il protège uniquement le navigateur.
Pour cela, le backend (API) doit avoir une liste des “origines autorisées”.
Exemple de configuration CORS dans FastAPI#
from fastapi import FastAPI
from fastapi.middleware.cors import CORSMiddleware
app = FastAPI()
app.add_middleware(
CORSMiddleware,
allow_origins=["https://frontend.exemple.com"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)Pour aller plus loin
Middleware d’authentification#
Rôle du middleware#
Un middleware d’authentification :
- intercepte toutes les requêtes
- vérifie la présence et la validité d’un token
- bloque la requête si nécessaire
Il s’agit d’un filtre global.
Exemple de configuration du Middleware dans FastAPI#
from fastapi import Request
from fastapi.responses import JSONResponse
from starlette.middleware.base import BaseHTTPMiddleware
import jwt
SECRET_KEY = "secret"
ALGORITHM = "HS256"
class AuthMiddleware(BaseHTTPMiddleware):
async def dispatch(self, request: Request, call_next):
# Routes publiques
if request.url.path in {"/health", "/docs", "/openapi.json"}:
return await call_next(request)
authorization = request.headers.get("Authorization")
if not authorization or not authorization.startswith("Bearer "):
return JSONResponse(
status_code=401,
content={"detail": "Unauthorized"},
)
token = authorization.replace("Bearer ", "")
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
request.state.user_id = payload["sub"]
except jwt.PyJWTError:
return JSONResponse(
status_code=401,
content={"detail": "Invalid or expired token"},
)
return await call_next(request)app.add_middleware(AuthMiddleware)Pour aller plus loin
Au lieu d’implémenter cette authentification « à la main », il est recommandé de consulter la documentation officielle de FastAPI sur l’authentification par jetons JWT. Cela pourra constituer des points bonus dans votre rendu final : OAuth2 with Password (and hashing), Bearer with JWT tokens