
Le Datalab fourni par l’équipe SSPCloud à l’INSEE est mis a disposition de divers publics.
Parmi ceux-ci:
- Chercheurs
- Agents de l’INSEE/ Ministères
- Etudiants de l’ENSAI/ENSAE
Pour découvrir le SSPCloud, accédez a la documentation dédiée ici : https://www.sspcloud.fr/document?path=SSPCloud%E2%90%A3Documentation%E2%80%BADiscover%E2%90%A3the%E2%90%A3Datalab%E2%80%BAFirst%E2%90%A3steps
Cette section à pour objectif de vous montrer des cas concrets d’utilisation du SSPCloud, comme un fournisseur cloud Kubernetes, pour votre workflow de travail.
Cela s’applique aussi dans les différents organismes dans lesquels vous travaillerez, en général il existe une instance de cloud interne ou l’utilisation d’un provider externe existe.
Utiliser le SSPCloud comme un fournisseur kubernetes#
Ici on va faire en sorte d’utiliser le SSPCloud comme un cloudshell ou autre côté google / AWS
Vous devez avoir kubectl d’installé et vous devez avoir un compte sur le SSPCloud.
Ensuite vous pourrez initier la configuration depuis :
Aller dans mon compte puis volet Connexion à Kubernetes
Copiez le script dans un terminal pour l’executer, il vous permet de brancher votre configuration locale au cluster SSPCloud.
Testez la viabilité de votre configuration avec la commande :
kubectl get podsVous devriez y voir des services qui vous concernent : un vscode par exemple.
Portforwarding#
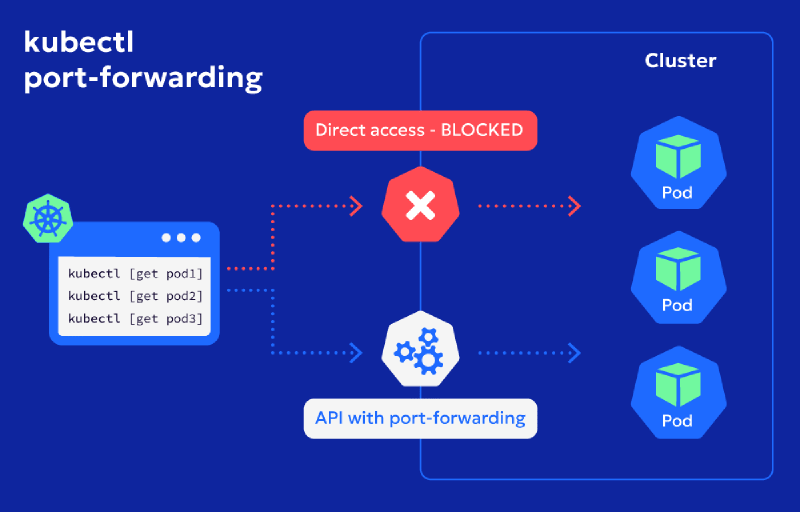
Lorsque vous travaillez avec des clusters kubernetes, vous pouvez utiliser ce que l’on appelle le port-forwarding. Cela permet de créer un tunnel sécurisé entre votre ordinateur et le service qui tourne sur le cluster Kubernetes.
Le port forwarding crée une connexion directe qui redirige le trafic réseau d’un port sur votre machine locale vers un port d’un pod dans le cluster.
Cela vous permet d’accéder à des applications ou services qui tournent dans le cluster sans avoir à les exposer publiquement. Ou de vérifier directement en local que votre application répond bien.
Utilisation simple : Debugging#
Comment cela marche ? Pour communiquer avec un cluster kubernetes, on utilise communément le binaire kubectl, il permet de dialoguer avec l’API.
Vous pouvez récupérer les services qui tournent sur votre namespace via la commande :
kubectl get podsTrouver les pods qui tournent sur son espace (donc dans son environnement onyxia)
Puis une fois ces pods trouvés on va pouvoir, par leur nom faire un tunnel pour pouvoir y accéder en local en local:
kubectl port-forward $POD portlocal:portconteneurEn remplaçant $POD par la valeur trouvée
exemple:
kubectl port-forward mon-api-abcdef-12345 1500:8000Après cette commande lancée, on peut accéder sur localhost:1500/* a notre application qui tourne sur le cluster.
Cela marche pour tout type de service: Base de données, Frontend, vscode, …
Utilisation avancée : Port-forwarding d’une base de données#
Idée
On souhaiterait pouvoir accéder a une base de données qu’on partage avec plusieurs personnes
Imaginons que nous sommes dans une équipe de 3 et qu’une personne installe la base de données dans son espace namespace.
On souhaiterait donc pouvoir y accéder, or cette base de données n’est accessible que depuis l’intérieur du cluster.
La personne qui a installé la base de données va pouvoir y accéder simplement en faisant :
kubectl port-forward postgres-abcdef-12345 5432:5432En allant chercher le nom du POD postgres
Ici on a mis 5432 pour le port du postgres
Et cela marchera uniquement pour la personne qui possède le namespace, le cluster propose une protection dans l’accès aux traitements des autres personnes via le namespace.
Nous avons donc perdu c’est ça ?
Rendre sa base de données accessible depuis un autre namespace#
Non, lorsque vous créez une base de données, vous créez ce qu’on appelle un service. Ce service permet d’accéder via un chemin a l’interieur du cluster à notre base, sans notion de namespace. C’est une option qui est cochable à la création de la base de données :
Catalogue de service
=>
Postgres / Mongo /…
=>
Security
=>
décocher only allow access from the same namespace
Maintenant la base de données est accessible a connexion d’en connaître le chemin et les credentials depuis le cluster.
Il faut combiner cette logique avec des outils de routage réseau pour que l’on puisse envoyer des données et en recevoir depuis notre namespace vers notre base de données, et que nous puissions de manière transparente accéder a un autre service de base de données ou autre exposé sur le cluster.
Accéder a la base de données de manière transparente, exemple avec socat#
Nous vous proposons ici d’utiliser socat un outil qui permet de faire de l’écoute et de la transmission via TCP (protocole d’échange de données utilisé par exemple par les bases de données).
Ainsi dans votre espace de travail vous pourriez mettre en place un tel Pod, qui sert uniquement a faire rebond pour vos opérations TCP vers la base de données.
En voici la définition en yaml
apiVersion: v1
kind: Pod
metadata:
name: pg-proxy
spec:
containers:
- name: socat
image: alpine/socat
args:
- TCP-LISTEN:5432,fork
- TCP:postgresql-cnpg-951239-rw.user-XXXXXXXX.svc.cluster.local:5432Vous pouvez le déployer en remplaçant user-XXXXXX par le user-USERNAME de la personne qui a envoyé.
Rappel
Pour déployer un contrat YAML en tant que fichier (ici monfichier.yaml) il faut utiliser la commande
kubectl apply -f monfichier.yamlEt ensuite vous pouvez vous y brancher directement :
kubectl port-forward pod/pg-proxy 5432:5432Et vous connecter à la base de données a partir des informations fournies par vos collègues.
Gérer des droits d’accès a des ressources de vos namespace#
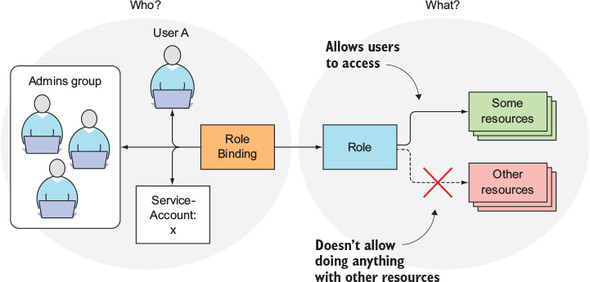
Au lieu d’ouvrir vos services sur le cluster vous pouvez aussi directement gérer des droits dans votre namespace.
Kubernetes offre des ressources de type Role RoleBinding qui vous permettent de définir des droits d’accès a certaines ressources de votre namespace via des rôles, et ensuite de faire du binding entre ce droit et des utilisateurs (donc vos collègues).
Cela donne une configuration du style :
Un rôle pour permettre le portforward du service qui s’appelle postgresql-cnpg-951239-rw dans mon namespace
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: postgres-service-portforward
rules:
- apiGroups: [""]
resources:
- services
- services/portforward
resourceNames:
- postgresql-cnpg-951239-rw
verbs:
- get
- createet une association avec les personnes qui ont le droit de l’utiliser :
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: postgres-service-portforward-ensai
namespace: mon-namespace
subjects:
- kind: User
name: user-XXXXXX
apiGroup: rbac.authorization.k8s.io
- kind: User
name: user-XXXXXX
apiGroup: rbac.authorization.k8s.io
- kind: User
name: user-XXXXXX
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role
name: postgres-service-portforward
apiGroup: rbac.authorization.k8s.ioIci user-XXXXX est a remplacer avec des gens de votre équipe.